





DeepSeek-R1, NVIDIA dichiara prestazioni di inferenza da record grazie alle GPU Blackwell

NVIDIA ha annunciato prestazioni record per l'inferenza IA con le GPU Blackwell con l'enorme modello DeepSeek-R1 da 671 miliardi di parametri. A giocare un ruolo fondamentale i Tensor core con supporto FP4.
di Manolo De Agostini pubblicata il 19 Marzo 2025, alle 09:21 nel canale Schede VideoBlackwellDeepSeekNVIDIA
NVIDIA ha annunciato di aver raggiunto prestazioni da record per l'inferenza del modello DeepSeek-R1 durante il GTC 2025. Un singolo sistema NVIDIA DGX dotato di otto GPU NVIDIA Blackwell può raggiungere oltre 250 token al secondo per utente o una velocità massima superiore a 30.000 token al secondo sull'enorme modello DeepSeek-R1 da 671 miliardi di parametri. Questi progressi sono stati possibili grazie ai miglioramenti dell'ecosistema NVIDIA per l'inferenza, ora ottimizzato per l'architettura Blackwell.
NVIDIA ha aumentato il throughput del modello DeepSeek-R1 di circa 36 volte rispetto alle prestazioni di un'analoga piattaforma H100, con un miglioramento di circa 32 volte del costo per token.
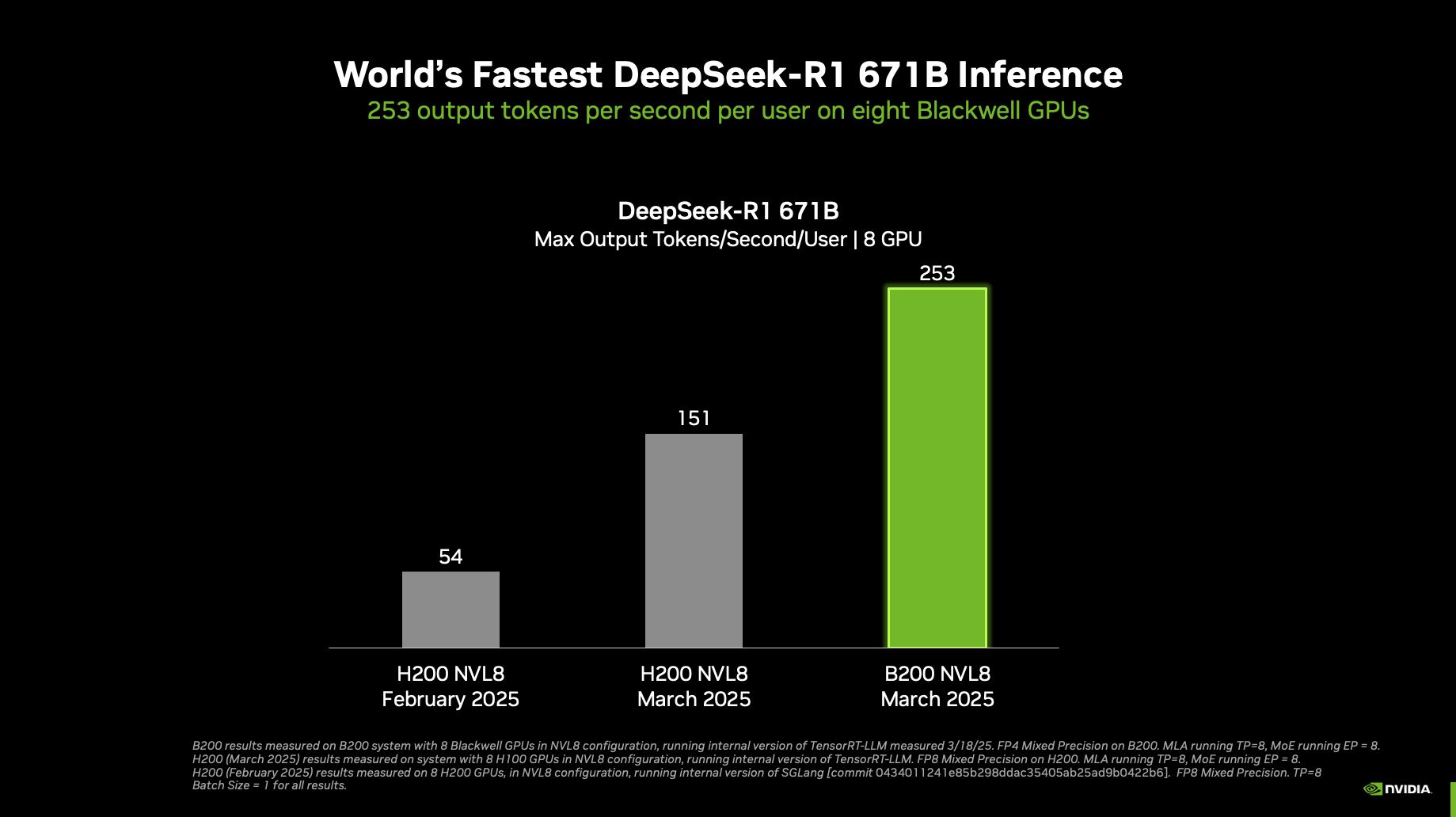
Clicca per ingrandire
Le GPU Blackwell offrono fino a 5 volte più potenza di calcolo IA grazie ai Tensor Core di quinta generazione grazie al supporto FP4, laddove le precedenti proposte Hopper si fermano a una precisione FP8. Inoltre, la nuova generazione di NVLink e NVLink Switch raddoppia la larghezza di banda, consentendo una scalabilità molto maggiore nei datacenter. Questi miglioramenti permettono un'inferenza ad alta velocità e bassa latenza, essenziale per modelli come DeepSeek-R1.
L'ecosistema TensorRT è un elemento chiave per ottimizzare l'inferenza su GPU NVIDIA. TensorRT Model Optimizer introduce tecniche di ottimizzazione avanzate, come la quantizzazione FP4, che migliora il throughput computazionale e riduce l'uso della memoria. Il software TensorRT-LLM 0.17, progettato con PyTorch, consente un'inferenza efficiente grazie a funzioni come in-flight batching, gestione della memoria KV cache e speculative decoding.
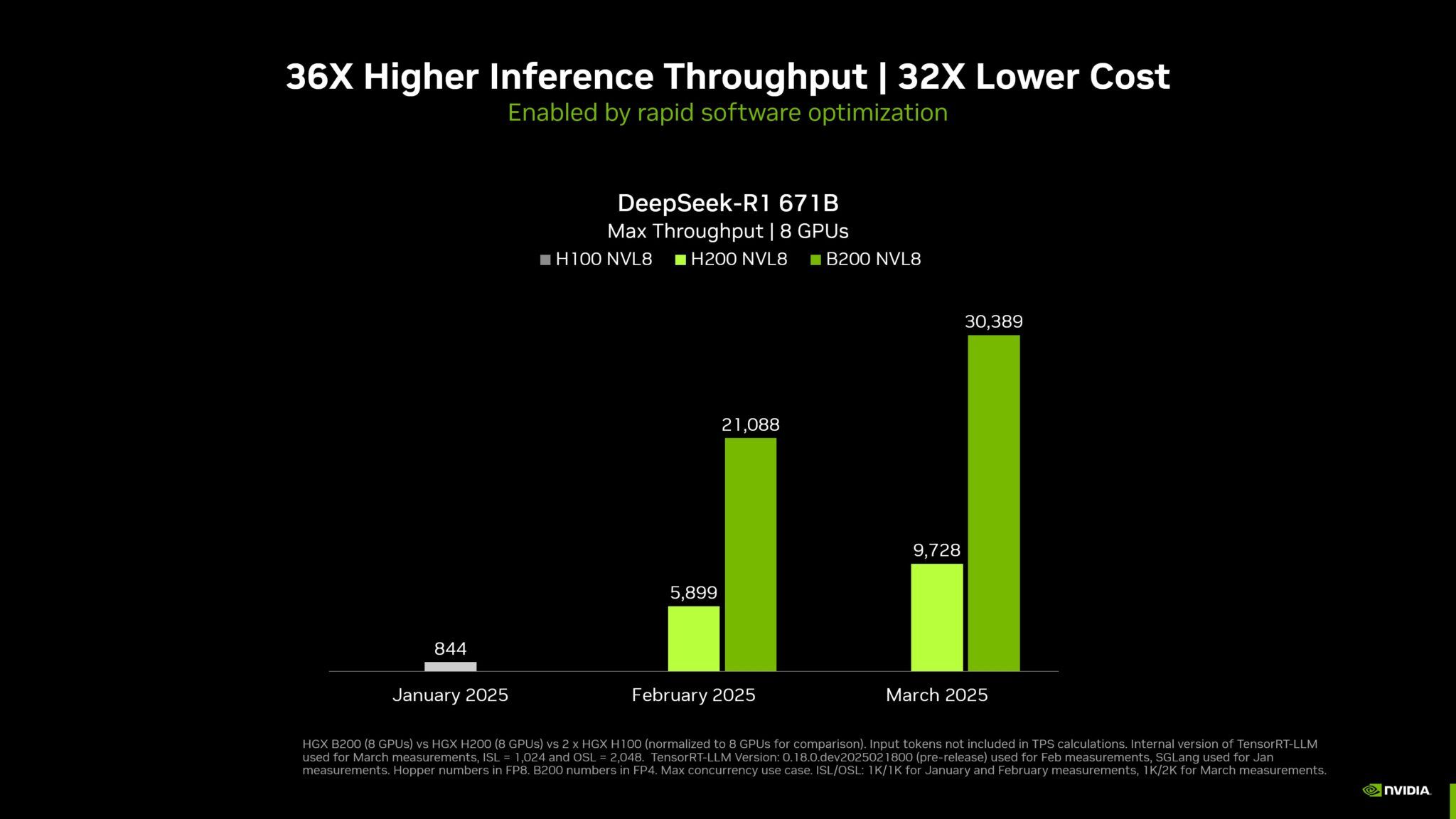
Clicca per ingrandire
"I modelli della comunità AI, come Llama 3.1 405B, Llama 3.3 70B e DeepSeek-R1, stanno già beneficiando delle migliorie offerte dalle GPU Blackwell. Rispetto alla generazione precedente, il sistema DGX B200 con precisione FP4 garantisce un throughput di inferenza oltre 3 volte superiore rispetto alle GPU H200 con precisione FP8", sottolinea NVIDIA.
L'uso della quantizzazione FP4 offre vantaggi significativi, con una perdita di accuratezza minima rispetto alla precisione FP8. Ad esempio, il modello DeepSeek-R1 con FP4 mostra una differenza inferiore all'1% rispetto alla versione FP8 su benchmark chiave come MMLU e GSM8K. Inoltre, la Quantization-Aware Training (QAT) aiuta a recuperare eventuali perdite di accuratezza, come dimostrato sui modelli Nemotron 4 15B e 340B, che ottengono prestazioni comparabili alle versioni BF16.



 Lenovo ThinkPad X9-14 Aura Edition: leggero e sottile per i professionisti
Lenovo ThinkPad X9-14 Aura Edition: leggero e sottile per i professionisti REDMAGIC 10 Air: potenza da gaming in un corpo leggero e moderno. Recensione
REDMAGIC 10 Air: potenza da gaming in un corpo leggero e moderno. Recensione Insta360 X5: è sempre la regina delle action cam a 360 gradi. Recensione
Insta360 X5: è sempre la regina delle action cam a 360 gradi. Recensione Intel: il nuovo CEO annuncia azioni forti, ma per ora nessun licenziamento di massa
Intel: il nuovo CEO annuncia azioni forti, ma per ora nessun licenziamento di massa La missione Shenzhou-20 ha effettuato il docking con la stazione spaziale cinese Tiangong
La missione Shenzhou-20 ha effettuato il docking con la stazione spaziale cinese Tiangong Xbox Cloud Gaming arriva sulle TV LG: verifica se il tuo televisore è compatibile
Xbox Cloud Gaming arriva sulle TV LG: verifica se il tuo televisore è compatibile Stellantis: batterie allo stato solido in arrivo il prossimo anno, ricarica in 18 minuti
Stellantis: batterie allo stato solido in arrivo il prossimo anno, ricarica in 18 minuti Effetto dazi, Logitech alza i prezzi fino al 25% negli USA: non è la sola tra aumenti e fuga
Effetto dazi, Logitech alza i prezzi fino al 25% negli USA: non è la sola tra aumenti e fuga Fondazione Carisbo entra in BI-REX. Obiettivo: accelerare e incubare startup
Fondazione Carisbo entra in BI-REX. Obiettivo: accelerare e incubare startup Dal 20 giugno 2025 arriva l'eco-label UE su smartphone e tablet: cosa cambia per i consumatori e venditori
Dal 20 giugno 2025 arriva l'eco-label UE su smartphone e tablet: cosa cambia per i consumatori e venditori Ionity installerà le prime colonnine Megawatt dell'italiana Alpitronic
Ionity installerà le prime colonnine Megawatt dell'italiana Alpitronic Realme GT7 ufficiale: specifiche da top di gamma a un prezzo super competitivo
Realme GT7 ufficiale: specifiche da top di gamma a un prezzo super competitivo Firefly arriva in Europa: si parte da 23.500 euro
Firefly arriva in Europa: si parte da 23.500 euro GeForce RTX 50: se avete acquistato una Gigabyte, controllate che il gel termico non stia colando
GeForce RTX 50: se avete acquistato una Gigabyte, controllate che il gel termico non stia colando 11 bit studios ha annunciato Frostpunk 1886: un remake in UE5 che andrà oltre la grafica
11 bit studios ha annunciato Frostpunk 1886: un remake in UE5 che andrà oltre la grafica Con NUS Enterprise Volume Agreement Nutanix semplifica la gestione di grandi volumi di dati
Con NUS Enterprise Volume Agreement Nutanix semplifica la gestione di grandi volumi di dati  STMicroelectronics: risultati in calo nel primo trimestre 2025, ma il CEO resta fiducioso nella ripresa
STMicroelectronics: risultati in calo nel primo trimestre 2025, ma il CEO resta fiducioso nella ripresa



























6 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infoGli FP 64 sono scomparsi dalle schede Nvidia.....
Da nessuna parte c'è scritto che Nvidia ha inventato qualcosa di nuovo.
C'è scritto che con i nuovi Tensor che supportano FP4 si raggiungono quelle prestazioni.
Secondo la tua affermazione, i calcoli "con i numeri piccoli" sono così semplici da implementare che chiunque, già da quando Huang giocava con i pupazzetti, era in grado di farli.
Ebbene, nel 2025, dopo 3 iterazioni della propria architettura, la maggior concorrente di Nvidia ancora non li supporta.
Poi però la stessa concorrente va in giro a spacciare bench fake dove compara quello che vuole con le ottimizzazioni che vuole, senza test di scaling, per dimostrare che le sue unità di accelerazione sono uno sputo superiori alle GPU di Nvidia della scorsa (o anche quella pima) generazione.
Nella realtà la differenza è abissale, soprattutto quando si parla di datacenter da migliaia e migliaia di acceleratori che devono lavorare in parallelo.
Sarà anche per questo che una azienda ha il 90% del mercato e le altre si litigano le briciole facendo passare le misere percentuali di vendita come una vittoria su cui investire.
P.S: i calcoli FP64 non sono mai serviti alla AI. Nvidia li ha messi in secondo piano da circa 8 anni nelle architetture per server e non li ha mai presi in considerazione per il mercato consumer. E infatti sta dove sta mica per nulla. Forse è perché è l'unica ad aver capito cosa realmente server per avere architetture super prestazionali ed efficienti per l'accelerazione AI.
Gli FP 64 sono scomparsi dalle schede Nvidia.....
poche idee e molto confuse
ti sei dimentico di scrivere l'inutile frase sulla concorrenza, ah no, l'hai usata per l'altra news
Ma smettila che Nvidia FP4 non c'è l'ha da nemmeno un anno.
Fra i paper launch (dove sono dei gran maestri), alle consegne effettive ne passa di acqua sotto i ponti...
Fra i paper launch (dove sono dei gra maestri), alle consegne effettive ne passa di acqua sotto i ponti...
Huh, devo aver toccato un tasto dolente ad un sostenitore AMD vedo.
Poverino, dai non ti preoccupare che tra 3 o 4 annetti anche AMD si presenta con i tensor core sul mercato consumer.
Poverino, dai non ti preoccupare che tra 3 o 4 annetti anche AMD si presenta con i tensor core sul mercato consumer.
Ma ti stai toccando da solo, perché se non sai le cose è un problema tuo
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".