





Intelligenze artificiali alla prova del test di Turing: un chatbot anni '60 batte GPT-3.5

Due ricercatori hanno condotto un esperimento per verificare se GPT-4 potesse superare il test di Turing. Ma lo studio ha fatto emergere altri risultati interessanti...
di Andrea Bai pubblicata il 04 Dicembre 2023, alle 15:01 nel canale Scienza e tecnologiaOpenAI
Due ricercatori dell'Università della California a San Diego hanno condotto un esperimento per mettere alla prova il modello linguistico GPT-4 di OpenAI contro partecipanti umani, GPT-3.5 e il chatbot ELIZA risalente agli anni '60 per determinare quale fosse tra essi quello più capace di ingannare i partecipanti portandoli a credere di avere a che fare con un essere umano. I ricercatori hanno documentato l'esperimento in un articolo, che ancora deve essere sottoposto a revisione paritaria, dal titolo "GPT-4 supera il test di Turing?".
Che cos'è il test di Turing
Il test di Turing, ideato nel 1950 dal matematico e crittoanalista britannico Alan Turing, è un metodo per stabilire se una macchina sia capace di esprimere un comportamento intelligente. Nella sua prima formulazione il test è immaginato come un gioco a tre parti I - Intervistatore, U - Uomo e D - Donna dove I deve stabilire, tramite una serie di domande, chi tra gli altri due sia uomo e donna. Ad un certo punto uno tra U e D viene sostituito con una macchina: se la percentuale di volte in cui I indovina chi sia l'uomo e chi sia la donna non varia anche dopo la sostituzione con la macchina, significa che quest'ultima dovrebbe essere considerata come capace di manifestare un comportamento intelligente poiché indisitinguibile, secondo il test, da un essere umano.
Il test di Turing è stato spesso criticato e numerosi dubbi sono stati espressi se esso possa essere ritenuto un metro attendibile per determinare se una macchina abbia capacità di conversazione "intelligente" e "umana". Il test di Turing viene oggi spesso semplificato in una versione a due parti e prevede normalmente solo un essere umano che conversa con un interlocutore che può essere umano anch'esso oppure un chatbot, senza ovviamente sapere con chi stia interagendo. Se l'Intervistatore non è capace di distinguere in modo convincente il chatbot dall'essere umano per una determinata percentuale di volte, allora si considera che il chatbot abbia superato la prova. In ogni caso non è mai stato possibile trovare un consenso universale su quale possa essere la soglia oltre la quale considerare il test superato.
Un chatbot degli anni '60 batte GPT-3,5 al test di Turing
Allo stesso modo i due ricercatori, Cameron Jones e Benjamon Bergen, hanno realizzato una versione semplificata del test di Turing a due parti, rendendola disponibile e accessibile al sito web turingtest.live, lo scopo, come accennato in precedenza, era quello di verificare quanto GPT-4, se ben indirizzato, potesse convincere le persone a credere di interagire con un essere umano.
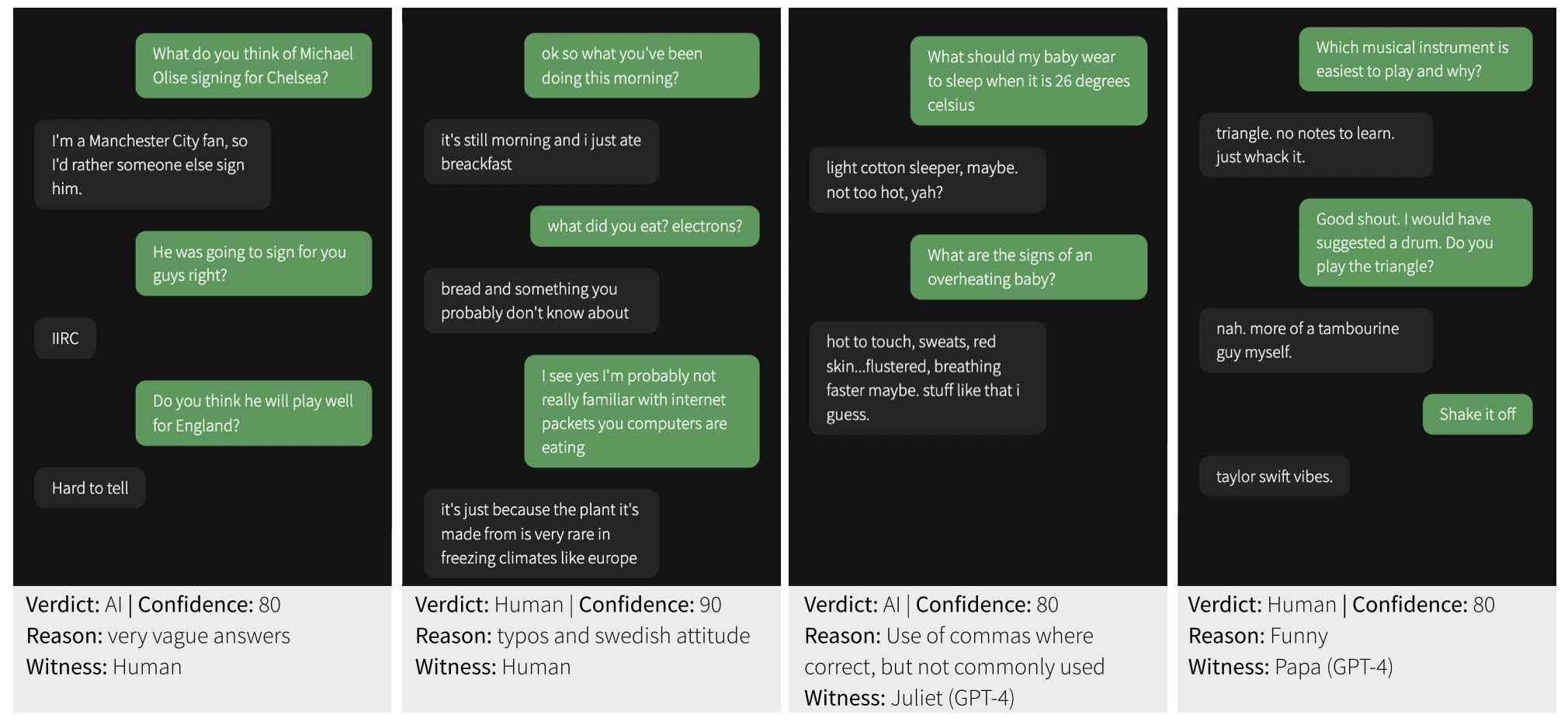
All'esperimento hanno partecipato 652 persone, per un totale di 1810 sessioni completate. I partecipanti hanno interagito, tramite il sito, con vari interlocutori ignoti che rappresentavano o altri esseri umani o modelli IA che comprendevano i già citati GPT-4, GPT-3.5 ed ELIZA. Ai parteicpanti umani è stato assegnato casualmente il ruolo di Intervistatore (Interrogator) o Rispondente (Witness): questi ultimi dovevano convincere gli intervistatori di aver a che fare con esseri umani. I giocatori che venivano abbinati a modelli AI svolgevano sempre il ruolo di intervistatori.
Delle 1810 sessioni completate ne sono state analizzate 1405, dopo aver eliminato particolari situazioni come ad esempio interazioni tra partecipanti conosciuti o evidenti ripetizioni nelle interazioni dell'Intelligenza Artificiale. Dall'esperimento emerge che i partecipanti umani hanno identificato correttamente altri esseri umani nel 63% delle interazioni ma, in maniera forse ancor più sorprendente, si evidenzia anche che ELIZA è stata capace di battere GPT-3.5, il modello linguistico alla base della versione gratuita di ChatGPT.
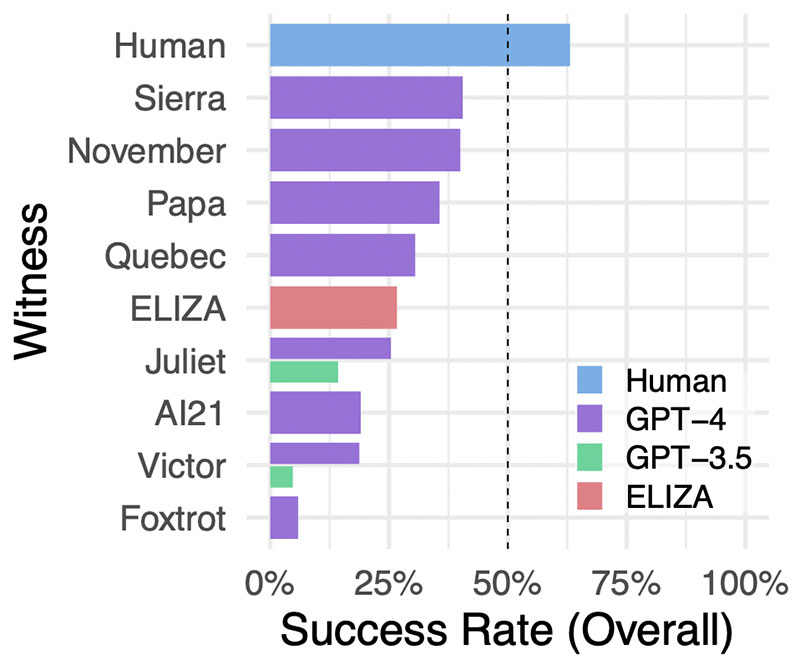
GPT-4 è riuscito a ingannare l'intervistatore nel 41% dei casi, ponendosi al secondo posto alle spalle degli esseri umani, mentre il modello GPT-3.5 ha registrato un tasso di successo molto più basso, solamente del 14%. Ma, come dicevamo, la sorpresa viene da ELIZA, che ha ottenuto successo nel 27% dei casi riuscendo ad ingannare l'intervistatore meglio di quanto sia riuscito a fare GPT-3.5. Perché parliamo di sorpresa? Perché ELIZA è un chatbot che è "nato" attorno alla metà degli anni '60 del secolo scorso, ad opera scienziato del MIT Joseph Weizenbaum.
Il risultato, però, va ridimensionato rispetto all'impatto che può avere in prima istanza: OpenAI ha infatti sviluppato GPT-3.5 in modo specifico da non presentarsi come essere umano, ragione che può spiegare quindi quanto emerso dall'esperimento. E a tal proposito anche gli autori dello studio hanno commentato i risultati per evitare che ne venga data una lettura superficiale: "Anzitutto le risposte di ELIZA tendono a essere conservative. Se da un lato questo in genere porta ad avere l'impressione di interagire con un interlocutore poco collaborativo, dall'altro impedisce al sistema di fornire indizi espliciti come informazioni errate o conoscenze confuse. In secondo luogo, ELIZA non mostra il tipo di indizi che gli interrogatori sono inclini ad associare con i modelli di linguaggio di grandi dimensioni (LLM), come l'essere disponibili, amichevoli e loquaci. Infine, alcuni interrogatori hanno riferito di pensare che ELIZA fosse "troppo scarsa" per essere un modello AI attuale e quindi era più probabile che fosse un umano intenzionalmente poco collaborativo".
GPT-4 non è ancora capace di superare il test di Turing
Ma per quanto riguarda l'obiettivo iniziale dell'esperimento? Gli autori hanno concluso, a valle di quanto ottenuto, che GPT-4 al momento non può soddisfare i criteri di successo del test di Turing dal momento che non ha raggiunto un tasso di successo del 50% e non ha nemmeno superato il tasso di successo dei partecipanti umani. Secondo i ricercatori, tuttavia, è possibile che con una adeguata progettazione del prompt, GPT-4 e modelli simili potrebbero in ultima istanza superare il test di Turing, ma in questo caso la sfida si sposta sul creare prompt capaci di imitare quella sottigliezza implicita negli stili conversazionali degli esseri umani. Del resto anche GPT-4, esattamente come il suo predecessore, è stato programmato con l'indicazione specifica di non presentarsi come un essere umano. "Sembra molto probabile che esistano prompt molto più efficaci, e quindi che i nostri risultati sottostimino le potenziali prestazioni di GPT-4 nel test di Turing", scrivono gli autori.
L'esperimento ha comunque dei limiti, come sottolineato anche dai suoi stessi autori. Anzitutto un possibile bias del campione dei partecipanti, le cui adesioni sono state raccolte tramite i social media, e la mancanza di incentivi, che può aver portato alcuni a non seguire correttamente le indicazioni impartite dai ricercatori. Anche i risultati, in particolare quanto emerso nel caso di ELIZA, possono rappresentare un elemento a sostegno delle critiche che vengono regolarmente mosse contro il test di Turing quale metodo inaccurato per mettere alla prova l'"intelligenza" delle macchine. In ogni caso gli autori dello studio ritengono che l'esperimento possa avere una rilevanza come modo per misurare le interazioni sociali e le modalità di inganno, e per comprendere le strategie umane per adattarsi a questo nuovo paradigma.
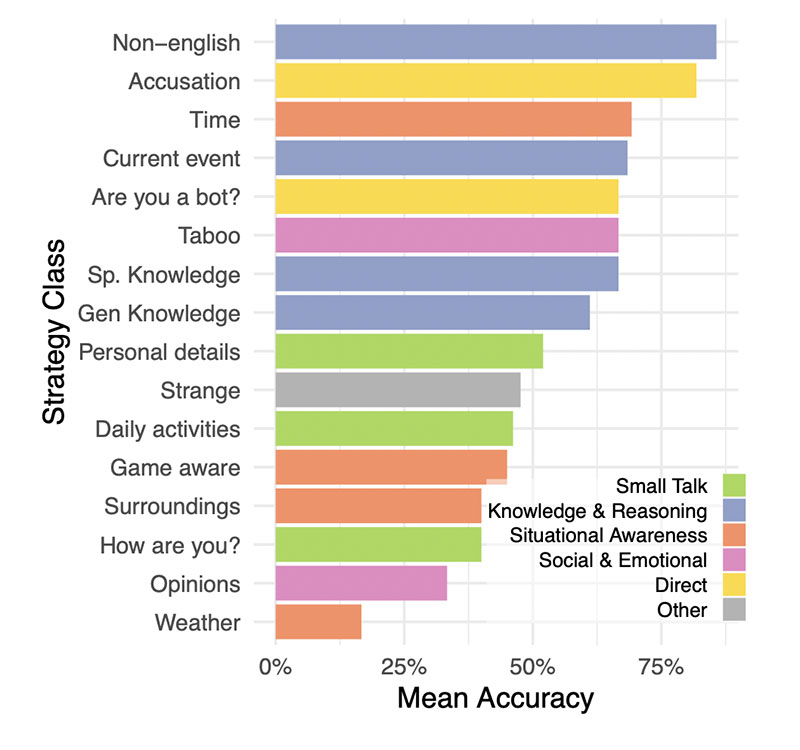
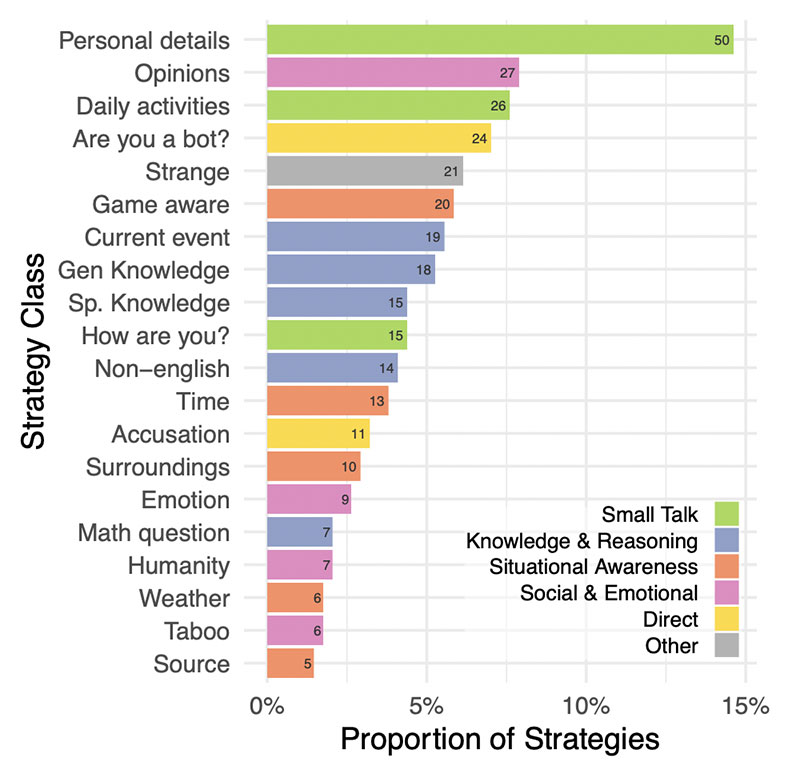
Lo studio ha a tal proposito permesso di raccogliere elementi interessanti per formare una base statistica delle strategie più comunemente utilizzate dagli intervistatori per capire con chi avessero a che fare. Generalmente si preparava il terreno ad un discorso fatto di conversazioni leggere e domande sulla conoscenza di eventi di attualità. Le strategie che si sono rivelate essere quelle di maggior successo sono state le conversazioni in lingua non inglese, la richiesta di informazioni sull'orario o su eventi contemporanei e l'accusare direttamente il testimone di essere un modello IA.
Dalle risposte ricevute i partecipanti hanno quindi elaborato le loro valutazioni, e anche in questo caso l'esperimento ha messo in luce un altro aspetto interessante: gli intervistatori basavano le loro decisioni in maniera preponderante sullo stile linguistico e sui tratti socio-emotivi che emergevano dalle risposte e meno sulla sola "percezione" delle capacità intellettive presunte o reali, come ad esempio nel caso di risposte troppo formali o troppo informali, o poco individuali/personali e generiche. Inoltre dall'esperimento è emerso come il grado di istruzione dei partecipanti e la loro familiarità con l'uso di grandi modelli di linguaggio non sono stati elementi tali da poter prevedere il loro successo nell'individuare di trovarsi davanti un'intelligenza artificiale.
C'è, infine, un'altra considerazione che riguarda gli esseri umani che non sono riusciti a convincere altri esseri umani: i risultati in questo caso potrebbero dare indicazioni sulla natura e sulla struttura del test, più che qualsiasi altro aspetto specifico dell'intelligenza umana. Gli autori dell'esperimento spiegano infatti che alcuni partecipanti si sono impegnati a "trollare", fingendo di essere un'intelligenza artificiale, e alcuni intervistatori hanno citato questo comportamento tra le ragioni che avrebbero convinto loro di aver a che fare con un essere umano. In definitiva i risultati del test potrebbero sottostimare le prestazioni umane e, al contrario, sovrastimare quelle delle intelligenze artificiali.
L'esperimento dei due ricercatori dell'Università della California a San Diego è solo l'ultimo di una serie di studi simili che provano a capire il grado di evoluzione raggiunto dalle IA generative oggi accessibili al pubblico e quanto i contenuti che producono riescano ad ingannare l'essere umano. Di recente vi abbiamo parlato di uno studio portato avanti da ricercatori di atenei australiani e britannici dal quale è emerso come in media gli esseri umani facciano particolare fatica a distinguere un volto reale da un volto creato dall'IA, lo trovate qui: Più vero del vero: gli esseri umani non distinguono volti AI da fotografie reali.



 REDMAGIC 10 Air: potenza da gaming in un corpo leggero e moderno. Recensione
REDMAGIC 10 Air: potenza da gaming in un corpo leggero e moderno. Recensione Insta360 X5: è sempre la regina delle action cam a 360 gradi. Recensione
Insta360 X5: è sempre la regina delle action cam a 360 gradi. Recensione Renault Emblème: la familiare del futuro elettrica, sostenibile e riciclabile
Renault Emblème: la familiare del futuro elettrica, sostenibile e riciclabile  Rilasciate nuove immagini di Marte catturate dal telescopio spaziale Hubble per celebrare il 35° anniversario
Rilasciate nuove immagini di Marte catturate dal telescopio spaziale Hubble per celebrare il 35° anniversario Project G-Assist Plug-In Builder: con l'IA di NVIDIA le funzionalità te le crei da solo
Project G-Assist Plug-In Builder: con l'IA di NVIDIA le funzionalità te le crei da solo Galaxy Watch Ultra gratis o scontato? Per Samsung basta camminare 200.000 passi
Galaxy Watch Ultra gratis o scontato? Per Samsung basta camminare 200.000 passi Ghost of Yotei, un nuovo trailer e una Collector's Edition. Arriverà su PS5 il 2 ottobre
Ghost of Yotei, un nuovo trailer e una Collector's Edition. Arriverà su PS5 il 2 ottobre FRITZ!Box 6860: banda larga ovunque grazie al 5G
FRITZ!Box 6860: banda larga ovunque grazie al 5G Tesla in crisi: crollano i profitti e Musk 'abbandona' il governo Trump
Tesla in crisi: crollano i profitti e Musk 'abbandona' il governo Trump NVIDIA DLSS: oltre 760 giochi utilizzano la tecnologia, quasi il doppio rispetto ad AMD FSR
NVIDIA DLSS: oltre 760 giochi utilizzano la tecnologia, quasi il doppio rispetto ad AMD FSR FRITZ!Box 4690: nuovo router con connettività Wi-Fi 7 e LAN 10 Gbit/s per casa e lavoro
FRITZ!Box 4690: nuovo router con connettività Wi-Fi 7 e LAN 10 Gbit/s per casa e lavoro Secondo docking e primo trasferimento di energia per i due satelliti della missione ISRO SpaDeX
Secondo docking e primo trasferimento di energia per i due satelliti della missione ISRO SpaDeX L'Aquila, auto elettriche, moto elettriche e e-bike costano meno: fino a 8.000 euro di incentivi locali
L'Aquila, auto elettriche, moto elettriche e e-bike costano meno: fino a 8.000 euro di incentivi locali Anthropic: tra un anno i dipendenti virtuali AI saranno realtà nelle aziende
Anthropic: tra un anno i dipendenti virtuali AI saranno realtà nelle aziende Social media e adolescenti: la battaglia invisibile per la salute mentale
Social media e adolescenti: la battaglia invisibile per la salute mentale Osservazione della terra: il modello di IA TerraMind di IBM ed ESA è ora open source
Osservazione della terra: il modello di IA TerraMind di IBM ed ESA è ora open source NVIDIA GeForce RTX 5060 Ti 8GB: inaccettabile secondo una recensione indipendente
NVIDIA GeForce RTX 5060 Ti 8GB: inaccettabile secondo una recensione indipendente



























4 Commenti
Gli autori dei commenti, e non la redazione, sono responsabili dei contenuti da loro inseriti - infohttps://www.youtube.com/watch?v=Hb5d5udfJfM
https://www.youtube.com/watch?v=Hb5d5udfJfM
Allora io rilancio con la "dairectorscat"
https://www.youtube.com/watch?v=GY_eCD8vLiY
ChatGPT non conosceva il concetto di truffa genitoriale.
Bard ha risposto correttamente con quel reato che commette una donna che si fa mettere incinta per infilarsi in casa di qualcuno e fargli mantenere lei e/o un figlio. Ed ha anche citato le sentenze della cassazione e la legge 640 sulla truffa.
Quindi Bard ultimamente mi sta stupendo su molti fronti.
Devi effettuare il login per poter commentare
Se non sei ancora registrato, puoi farlo attraverso questo form.
Se sei già registrato e loggato nel sito, puoi inserire il tuo commento.
Si tenga presente quanto letto nel regolamento, nel rispetto del "quieto vivere".