





|
|||||||


|



|
|
 |
|
|
Strumenti |
 31-07-2015, 20:07
31-07-2015, 20:07
|
#30041 | ||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4087
|
Quote:
L'AVFS contribuisce davvero poco: A 10W per modulo, permette frequenze superiori del 6% o di risparmiare un watt (9 invece di 10) a parità di frequenza (+11% in efficienza). Il grande vantaggio c'è a 5W per modulo: 14% di frequenza in più o 1,2W in meno (+32% in efficienza). A 2,5W per modulo AVFS permette frequenze più alte del 45% (parliamo di 1,7 vs 1,2 GHz). Un die shrink a 20nm ed excavator è già pronto per entrare in un smartphone. Pazzesco. A 22 Watt per modulo (interessante per gli octa-core da 95W) non esiste nessunissima differenza tra l'avere o no l'AVFS. A 25W per modulo assistiamo al sorpasso del HDL liscio. L'AVFS è un freno per le cpu ad alte prestazioni visto e considerato che seppur di pochissimo le librerie high performance fanno meglio delle HDL (2-3% di frequenza in più, ampiamente compensata dal maggior ipc di excavator). PS il confronto è con i 28nm HDL senza AVFS, tutte le misure le ho ricavate dalla slide. Quote:
approfondisco la mia risposta riguarda un rimaneggio del numero di stadi che compongono la pipeline (o meglio le pipeline, visto che parliamo di un architettura superscalare). Il tasso di esecuzione di una CPU a pipeline è fortemente influenzato dallo stadio più lento, il cosiddetto collo di bottiglia. Il caso ideale si ha quando tutti i segmenti richiedono un uguale tempo t. Il tempo di elaborazione del singolo stadio è la base sulla quale si costruisce la cpu: il famigerato FO4, ritardo normalizzato di uno stadio della pipeline, è un parametro essenziale nella progettazione di una nuova architettura (addirittura si fanno studi solo per determinarne il più adatto). Il FO4 è un obiettivo di progettazione. Se qualche blocco di codice non soddisfa questo obiettivo, deve essere ottimizzato ulteriormente o viene aggiunto un ulteriore stadio lungo la pipeline. Nel caso in cui uno stage presenta un fo4 basso, il tempo "vinto" potrebbe essere utilizzato per implementare una logica più efficiente o più grande (ad esempio aumento delle dimensioni del buffer) per migliorare le prestazioni. A proposito di FO4, quello di bulldozer è di 17 contro i 22 di k10/k8 e i 21 di k7. In linea teorica a parità di processo produttivo bulldozer può andare fino al 30% in più (quindi su 45nm il limite superiore è di 5GHz). Fino perchè va considerato il tempo di ritardo che ogni stadio introduce. Tuttavia con l'ausilio della maglia di condensatori, si è andati persino oltre: 35%..Sui 45nm steamroller, almeno nella versione esacore, avrebbe potuto girare a 4,4GHz/5,2GHz in turbo mode... C'è da fare un ulteriore differenziazione tra il FO4 dell'architettura e il ritardo del FO4 (delay) dovuto al processo produttivo. Per motivi apparentemente immotivati (per noi si intende) , un processo produttivo migliore può presentare un fo4 delay sfavorevole su uno o più stadi. Anche nel caso in cui il ritardo del fo4 risultasse più basso su tutti gli altri stadi, il fo4 complessivo del processore viene inevitabilmente compromesso. Può bastare una modifica leggera al design, altre volte le modifiche devono essere più profonde, magari con scelte che vanno a scapito del ipc. Per tutta una serie di motivi, resto dell’idea che qualsiasi maneggio della lunghezza delle pipeline in una moderna cpu, richieda modifiche profonde dell’architettura. Ultima modifica di tuttodigitale : 02-08-2015 alle 01:41. |
||

|

|

|
02-08-2015, 01:39
|
#30042 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30315
|
K.
Però quella tecnologia penso dipenda anche dalla linearità del silicio, cioè dove servirebbe il Vuole max da come scrivi influirebbe poco, ma nei p-state intermedi di più, sempre se non c'è una correlazione ad un certo valore di Watt, perché se parlassimo sino a 100 a core, Zen comunque sarebbe dentro i 10W, perché se 95Win 8 core, escludendo PCI, MC e tutto l'I/O, non è che si starebbe tanto distante dai 10W se non addirittura sotto. In ogni caso è probabile o almeno possibile che su Excavator mobile l'abbiano finalizzata per il campo mobile, cioè dando la priorità al minor consumo a scapito della prestazione massima, mentre se implementata su Zen con chiaro obiettivo alle massime prestazioni, la tipologia sarebbe differente. In ogni caso il 28nm ha un rendimento anche ben superiore al 32nm SOI sui15W, superiore sui 35W, per poi mano a mano decadere a 65W ed infine essere inferiore sopra i 65W. Di Zen si riporta una potenza superiore ma ancora non si è capito se questa viene tutta da un IPC superiore o in parte anche da frequenze superiori Però a me non è chiaro una cosa... e semplifico in modo grossolano. Io mi immagino le unità logiche INT e FP del Phenom II con potenza 8, ed in BD l'INT è stato potenziato (un mix di cose, tra set di istruzioni nuove e cicli più rapidi e/o meno cicli a istruzione e/o più istruzioni a parità di cicli) e l'FP è stata si condivisa, ma è passata da 128 bit a 256 (il Phenom II non supporta le AVX). In linea teorica, quindi, ci dovremmo trovare che il modulo BD dovrebbe avere un IPC superiore al Phenom II, perché avrebbe la parte INT più potente di quella Phenom II e un FP condivisa che comunque risulterebbe doppia di quello del Phenom II, quindi, considerando che a 128 bit sarebbero 2, ogni core del modulo avrebbe una FP tale e quale a quella del core Phenom II. Io ho sempre avuto l'idea che la mancanza di IPC non sia stata a causa della condivisione in sé, ma al fatto che le unità logiche fossero "alimentate" male, come ad esempio nel passaggio da Zambesi a Piledriver, non è stato fatto nulla nelle unità logiche ma semplicemente aggiunta una pipeline alla parte MMX della FP. Di Steamroller non so molto, ma credo che la strada sia sempre stata quella di rendere più efficiente l'alimentazione alle unità logiche più che potenziarle. Sempre a fantasia, faccio un esempio: Intel non ha una FP doppia per il secondo TH nell'HT ma semplicemente è velocissimo a svuotare la L1 ed utilizzare nel tempo "morto" tutto il potenziale del procio che non è sfruttato. Quindi essenzialmente non è una potenza in sé delle unità logiche, ma semplicemente che queste lavorano al max (considerando che, se si riesce a sfruttare il tempo "morto" la circuiteria indubbiamente deve essere veloce e di conseguenza alimenterebbe più che bene i cicli del core già nella condizione senza HT e di qui più IPC Quello che per me è incomprensibile, è che AMD perda un totale di IPC nel core, ma molto meno nel modulo con 2 TH. Cioè... Quando in effetti il modulo BD si comporterebbe similmente ad un core +HT Intel (cioè 2 TH sulle stesse unità logiche FP) il modulo recupera tantissimo, mentre con 1 TH e quindi forza bruta, si siede. Cioè... non riesco ad inquadrare il punto di delimitazione cioè dove Intel è brava o dove AMD invece operi malissimo. Spiegando meglio, sarebbe come se il modulo BD operasse 2 TH fisici fisici sugli INT ed un TH fisico ed uno logico sull'FP e qui ci sta la differenza tra fisico e logico ed AMD guadagnerebbe. Ma quando si passa al core, Ok che Intel guadagnerebbe per la gestione HT, ma in fin dei conti AMD avrebbe una FP fisica mentre Intel comunque la deve condividere nell'HT. Cioè, se il modulo arriva li li con 2 TH, la differenza con 1 TH dovrebbe essere del 30% circa, ma non del 50% o del 45% senza HT. P. S. Il confronto ipotetico lo farei a parità di set di istruzioni, nel senso che è chiaro che se si confrontasse una FP Intel che risolvere le AVX2 nativamente Vs un Piledriver che max si ferma alle AVX, la differenza di IPC sarebbe ovvia, come è ovvio che un FX Piledriver non ha tutte le implementazioni di Steamroller/Excavator, quindi andrebbe confronto questi ultimi con una proiezione immaginaria di un FX X8, tanto Zen è distante e comunque migliore.
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M Ultima modifica di paolo.oliva2 : 02-08-2015 alle 08:05. |
|
|
|
|
02-08-2015, 11:30
|
#30043 | |||||||||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4087
|
Quote:
Quote:
Quote:
E ancora il a10-7800 da 65W (3,5GHz), consuma 15W in meno. A 45W non c'è proprio confronto, visto che kaveri ha velocità di clock superiore del 25-30%. Quote:
Quote:
Quote:
Un test sintetico di questo tipo serve proprio per testare la potenza grezza degli int e della fpu (infatti tra bulldozer e piledriver non ci sono differenze) Quote:
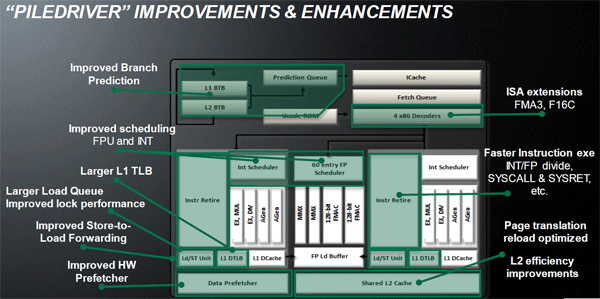 Modifiche effettuate in steamroller: 1) decoder dedicati per ogni cluster 2) aumentata la dimensione della cache istruzione 3) migliorata l’efficienza del dispatch 4) introduzione delle micro ops fusion nella fase di decodifica 5) ulteriori miglioramenti del predittore rami e per quel dato sapere al momento di excavator hanno modificato, per l'ennesima volta la cache l1 (3 su 3) e ridotto la cache l2 (aumentandone la velocità?) Quote:
PS il fatto che la fp unit abbia diverse pipeline, il fatto di poter gestire più thread può significare che la fpu è tanto ampia che la cpu non riesca comunque estrarre abbastanza ILP da saturarla. Quindi in realtà la fpu di nehalem aldilà della flessibilità potrebbe essere molto più ampia e potente di quelle viste nell'architettura di AMD. forse ho trovato la risposta le pipeline della fpu di SB sono composte da due "canali" da 128bit. C'è un ritardo di un ciclo di clock per trasferire i 128bit lsb e i 128 bit più significativi. I due registri non sono trattati come indipendenti fatta eccezione per il "saved state" . Apparentemente le due metà sono trasmesse completamente nel "modified state". Quindi la FP unit di INtel non ha la flessibilità della fpu di AMD. Le pipe sono 3 Ho scoperto una cosa interessante su BD, le pipe sono 4, ma sono passati a 3 con steamroller. Non che la cosa non fosse stata resa pubblica: 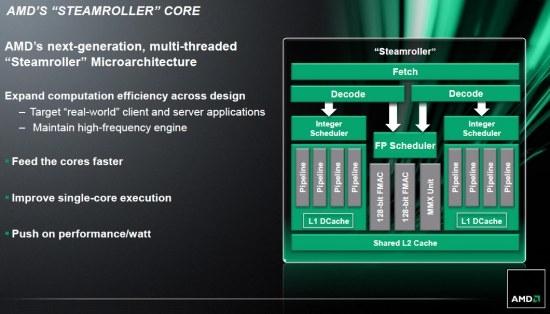 Nonostante ciò lo scaling in cinebench, noto per essere un test fp-intensive, è ottimo. La FPu probabilmente era sovradimensionata alle capacità dell'architettura. Addirittura in Piledriver abbiamo un troughput molto peggiore d bulldozer con i dati a 256 bit. Mentre steamroller fa molto meglio di entrambi: sono richiesti 3 cicli di clock nel caso allineato per bd e 10 se non allineati (17 per piledriver). Steamroller fa scendere questi valori rispettivamente a 2 e a 4. Quindi in BD/PD si hanno 4 pipe da 128 bit contro 3 ma a 256bit di Intel e le 3 a 128bit di k10 e SR... Effettivamente un +50% su k10, significa che in media ogni pipeline permette mediamente un aumento delle prestazioni del 13% a parità di clock. La super fp unit di bulldozer non sembra più tale da questa prima analisi superficiale Quote:
Ultima modifica di tuttodigitale : 02-08-2015 alle 14:52. |
|||||||||
|
|
|
|
03-08-2015, 09:40
|
#30044 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30315
|
Al momento sono in Italia ed i provi li ho lasciati in Africa.
Io non ho la tua competenza, ma credo che si possa creare questa situazione: Metto valori indicativi... CMT - 20%. Modulo con 1 core disattivato +10% (valori a spannella che ricordo) Può darsi che nei bench ci sia una media (INT e FP) e che il guadagno sia riferito solo all'FP in quanto sulla parte INT il CMT non influirebbe (a parte forse l'attesa di un dato dall'FP), ma è possibile che i canali all'FP siano studiati per 2 core e nel caso di disattivazione di un core, questi non siano sufficienti a sfruttarla al 100%. ----- Comunque è giusto il mio pensiero? Cioè, penso che alla radice una ALU AMD o Intel (scartando set di istruzioni proprietarie o se simili) abbiano circa la stessa potenza. La superiorità Intel sta nell'alimentarle il più velocemente possibile (come predizione, come rapidità cache e quant'altro). Il CMT può essere anche visto come alternativa, cioè, se AMD non riesce a fare quello che Intel fa (ma può anche dipendere dal silicio) mettere 2 canali di alimentazione dati sull'FP poteva anche avere un effetto simile all'HT ma probabilmente si è ancor più incasinato l'insieme e (forse) a causa di un silicio che genera più TDP del previsto, hanno dovuto snellire la parte alimentazione e/o comunque senza apportare aumenti consistenti di transistor. Non mi sembra un caso che comunque gli incrementi di potenza coincidono con la disponibilità di silicio migliore Steamroller dà più di Piledriver ma nei 15/35W del 28nm bulk Excavator va più di Steamroller perché si è fatto in modo che il core generi più potenza a parità di TDP con opportune modifiche nel rapporto transistor/consumo Zen andrebbe di più, ma cacchio, da un 32nm/28nm si passerebbe a 16nm/14nm, questo lascerebbe un gran margine di TDP e numero di transistor/core... Per dare una idea, si potrebbe passare da 4 moduli/8 core per 125W a 8 core con gli stessi transistor del modulo BD e addirittura abbassare a 95W il TDP. In fin dei conti l'evoluzione modulo da Piledriver a Steamroller non sabbie stata possibile allo stesso TP/frequenze/numero di core su FX, ma possibile unicamente sul 28nm bulk nei 15/35W (il confronto Trinity-kaveri è impietoso). Il passaggio Steamroller-Excavator con il controllo Vcore/frequenze ha portato un vantaggio dal 10 al 30% sul TDP finale, e siccome i gradini del TDP commerciale sono gli stessi, lo spazio TDP si è incrementato. AMD di certo le colpe le ha, ma è innegabile che sviluppo d incremento prestazionale siano strettamente dipendenti dal silicio disponibile.
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M Ultima modifica di paolo.oliva2 : 03-08-2015 alle 09:57. |
|
|
|
|
03-08-2015, 15:05
|
#30045 |
|
Bannato
Iscritto dal: Aug 2001
Città: Bergamooo...
Messaggi: 20089
|
R15 a def del mio nuovo sistemino
Win 7 64bit vanilla 642 punti Essendo ad aria con un noctua doppia ventola che punta alla silenziosità più che alla prestazione, non ho particolari aspettative........ vediamo dove arrivo a vdef con turbo spento...... e poi decidiamo quale oc daily impostare.....il batch sembra buono, su oc.net ho visto un 4,7 a 1,404v con la mia stessa mobo (asus crosshair formula v z) a liquido. Poi quando liquiderò pure io se ne riparlerà |
|
|
|
|
03-08-2015, 19:55
|
#30046 | |
|
Senior Member
Iscritto dal: Jun 2002
Città: Bolzano
Messaggi: 916
|
Quote:
Ho raggiunto stabilmente (prima del cambio case e AIO) a 4.3 cpu volt 1.30 e cpu/nb a 1.225 mentre a 4.7 cpu volt 1.30625 e cpu/nb a 1.225. La mia domanda è la seguente, visto che questa "para" delle temperature e dei voltaggi mi è venuta solo dopo che ho preso 9370, con 8350 di prima che valori avevo di default? Solo per sapere, non ho mai fatto test e robe simili, per un pò lo avevo tenuto a 4.4 con 21x205, gli unici test erano i giochi. Saluti...
__________________
AMD FX 9370, asus M5A99FX,16 gb 1866, EVGA 680 classified 4GB, 3xssd, win 10 pro 64. Ho concluso positivamente con 25 utenti (chiedere in pvt lista) e ultimamante con: salemme80, Amph, TH4N4TOS, gtx660ti, coontrol86, ChriD, iktus, liquidoso, Walker82xx, bad_lama, Legolas84, JollyRoger85, Nacar, ysc... |
|
|
|
|
|
03-08-2015, 20:54
|
#30047 | |
|
Senior Member
Iscritto dal: Nov 2003
Città: Siena
Messaggi: 17015
|
Quote:
correzione l'8350 con vcore a 1,275 tiene i 4,6 con 1,38v (rileggendo mi sono accorto dell'errore  ) )
__________________
1°Pc 1600X@4Ghz+Master liquid 240+B350-F+EVGA 750w+970 strix 4gb+M.2 Crucial 256Gb+hd 1 ST 4Tb+1 ST 4Tb+2x8Gb G.Skill Ripjaws 3200@2933 2°Pc R7 2700X@default+NH-D14+Asus X370 pro+XFX 750ww+cross 2X480 8gb+hd M.2 pcie samsung 240gb+hd WD 2Tb+3Tb+2x8Gb G.Skill flarex 3200@3200 3°Pc Kabini 5150+AM1M-A+Seagate 320Gb+2x2Gb Kingston 1600mhz+skystar2 eXpress HD 4°Pc QC5000M-ITX/PH+RemixOS Ultima modifica di isomen : 06-08-2015 alle 23:32. |
|
|
|
|
|
03-08-2015, 20:58
|
#30048 | |
|
Senior Member
Iscritto dal: Nov 2003
Città: Siena
Messaggi: 17015
|
Quote:
__________________
1°Pc 1600X@4Ghz+Master liquid 240+B350-F+EVGA 750w+970 strix 4gb+M.2 Crucial 256Gb+hd 1 ST 4Tb+1 ST 4Tb+2x8Gb G.Skill Ripjaws 3200@2933 2°Pc R7 2700X@default+NH-D14+Asus X370 pro+XFX 750ww+cross 2X480 8gb+hd M.2 pcie samsung 240gb+hd WD 2Tb+3Tb+2x8Gb G.Skill flarex 3200@3200 3°Pc Kabini 5150+AM1M-A+Seagate 320Gb+2x2Gb Kingston 1600mhz+skystar2 eXpress HD 4°Pc QC5000M-ITX/PH+RemixOS |
|
|
|
|
|
04-08-2015, 08:50
|
#30049 | |
|
Senior Member
Iscritto dal: Jun 2002
Città: Bolzano
Messaggi: 916
|
Quote:
Quindi ogni cpu è diversa dall'altra, anche se della stessa serie, sapevo già che i pezzi migliori venivano "promossi" a cpu superiori. Io pensavo che tutti gli 8350, per esempio, avessero caratteristiche uguali, oltre che alla frequenza. La mia cpu se fosse capitata in mani ad uno ancora più inesperto di me si sarebbe trovato una "stufetta" sotto la scrivania...
__________________
AMD FX 9370, asus M5A99FX,16 gb 1866, EVGA 680 classified 4GB, 3xssd, win 10 pro 64. Ho concluso positivamente con 25 utenti (chiedere in pvt lista) e ultimamante con: salemme80, Amph, TH4N4TOS, gtx660ti, coontrol86, ChriD, iktus, liquidoso, Walker82xx, bad_lama, Legolas84, JollyRoger85, Nacar, ysc... |
|
|
|
|
|
04-08-2015, 09:29
|
#30050 | |
|
Senior Member
Iscritto dal: Nov 2003
Città: Siena
Messaggi: 17015
|
Quote:
__________________
1°Pc 1600X@4Ghz+Master liquid 240+B350-F+EVGA 750w+970 strix 4gb+M.2 Crucial 256Gb+hd 1 ST 4Tb+1 ST 4Tb+2x8Gb G.Skill Ripjaws 3200@2933 2°Pc R7 2700X@default+NH-D14+Asus X370 pro+XFX 750ww+cross 2X480 8gb+hd M.2 pcie samsung 240gb+hd WD 2Tb+3Tb+2x8Gb G.Skill flarex 3200@3200 3°Pc Kabini 5150+AM1M-A+Seagate 320Gb+2x2Gb Kingston 1600mhz+skystar2 eXpress HD 4°Pc QC5000M-ITX/PH+RemixOS |
|
|
|
|
|
05-08-2015, 16:46
|
#30051 | |
|
Bannato
Iscritto dal: Aug 2001
Città: Bergamooo...
Messaggi: 20089
|
Quote:
L'FX è sul pc in garage  metti che la vespa vuole vedere qualcosa su iutubbe..... metti che la vespa vuole vedere qualcosa su iutubbe.....Sto weekend spero di montare tutto nel raven e iniziare a alzare il multi del FX
|
|
|
|
|
|
05-08-2015, 18:21
|
#30052 | |
|
Senior Member
Iscritto dal: Jan 2013
Messaggi: 4225
|
Quote:
|
|
|
|
|
|
05-08-2015, 22:45
|
#30053 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30315
|
Fare anticipazioni sui silicio è un terno al lotto.
Ho letto l'articolo sulle nuove cpu a 14nm Intel. Io mi aspettavo un TDP molto inferiore al 22nm, un rapporto consumo/prestazioni un 20% inferiore almeno ed un OC inferiore. Non ci ho beccato una mazza... Consumi e TDP quasi simili, ed addirittura a naso, visto i @4,7GHz raggiunti mi pare facilmente, mi da' l'idea addirittura che si occhi meglio il 14nm del 22nm. Ribaltando il tutto ad AMD, io fino ad ora mi ero ipotizzato che gli OC del 32nm SOI >5GHz sarebbero stati un bel ricordo e che già sarebbe stato bello avere le stesse frequenze Def di 4GHz. Cacchio... Intel, considerando che alla prima sfornata del 22nm era a 3,5GHz, massimi, ha guadagnato la bellezza di 500MHz, e se non ricordo male, già ora con la stessa facilità (o difficoltà, a picere) circa 300MHz in OC. Ma non si parlava che Intel aveva qualche problema sul 14nm?
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M |
|
|
|
|
05-08-2015, 23:07
|
#30054 | |
|
Senior Member
Iscritto dal: Mar 2006
Città: Rovigo
Messaggi: 1204
|
Quote:

__________________
CASE: Pure Base 500DX nero | MB: Msi Mag B550 Tomahawk | CPU: AMD Ryzen 5 3600 | COOLER: Noctua NH-C14S | PSU: XFX Pro Series 450W | RAM: Crucial Ballistix 2x8gb 3600mhz C16 | SSD: WD BLACK SN850 1 TB | Samsung 850 Evo 500GB | HDD: WD Green 500GB | Seagate Barracuda ST4000DM004 VGA: XFX Radeon RX 580 GTS XXX Edition | OS: Windows 11 STEAM |
|
|
|
|
|
05-08-2015, 23:35
|
#30055 | ||||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4087
|
Quote:
Sul maggior utilizzo della FP unit con il secondo thread non ho dubbi al riguardo. Semmai sul quantitativo del suo contributo. Quote:
Alimentarle il più possibile significa avere tutta una serie di accorgimenti circuitali di una complessità probabilmente tale da non rientrare nei limiti del FO4 stabilito in fase di progetto. L'ipc ha un costo lato frequenza, c'è poco da fare. La scelta di averne solo 2 può giovarne lato consumi (meno, molto meno per il risparmio di spazio sul die). Quote:
Il CMT lo vedo come il fratello povero del SMT, ovvero un SMT parziale efficace solo nell'utilizzo della fp unit. Quote:
Secondo me, un +8% sul ST e +40% nel dual-thread, è possibile con "semplici" modifiche. Si prende il core excavator, si aumenta il numero dell'unità esecutive del 50% (da 2 a 3 ALU, da 3 a 5 pipe della fpu), si aggiunge con alcune modifiche HW il SMT senza aumentare la potenza del front-end di piledriver, sufficiente per alimentare un core e mezzo. Ovviamente quello che scrivo è pura fantasia, tutto per sottolineare che in fondo il +40% a parità di core e frequenza, non è così esagerato..Speriamo piuttosto che il SMT dia un contributo minimo (diciamo 10-15%), e che le risorse int vengano utilizzate meglio nel ST. teoricamente un doppio die shrink dovrebbe permette un dimezzamento dei consumi insieme ad un aumento, minimo, di frequenza. Quindi, se il 40% fosse confermato anche lato prestazioni (ovvero zen girasse a 4GHz), non mi sembra un risultato poi così fuori portata. Un doppio die shrink per andare "solo" il 40% (65%?) più di excavator (piledriver), consumando il 30% in meno è nelle corde di AMD, soprattutto se consideriamo il debaclé dei 32nm SOI. (dal 65 ai 45nm low k addirittura l'efficienza è aumentata ben oltre al 100%, senza considerare l'aumento dell'ipc della seconda revisione di k10..) Ultima modifica di tuttodigitale : 06-08-2015 alle 00:04. |
||||
|
|
|
|
06-08-2015, 22:18
|
#30056 | |
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4087
|
Quote:
non è detto che le capacità del silicio 22nm al debutto siano state sfruttate al massimo, e comunque invito sempre a non guardare il TDP dichiarato, ma il consumo effettivo, quei 500MHz aggiuntivi richiedono 15W extra, un inerzia certo, considerando il boost. Su tomshw ad esempio, il 4770k al debutto è stato occato a 4,7 GHz contro i 4,6 del i7 4790k...entrambi erano esemplari destinati alla stampa. Bisogna anche tener presente che le capacità del primo haswell in OC sono state fortemente limitate dalla pasta del capitano 1.0, come dimostrano gli 8°C in più nonostante un consumo inferiore rispetto al i7 4790k. Anandtech riporta in una tabella un regressione delle capacità di raggiungere certe frequenze che si è avuta da SB fino a broadwell, sembra che sklake abbia invertito un poco la tendenza, ma parliamo di cifre percentualmente insignificanti. http://www.anandtech.com/show/9483/i...h-generation/6 Dalle recensioni che ho visto, le capacità di OC di Broadwell non mi sembrano poi così buone, chi si è fermato ad un modesto 4,3GHz chi a 4,6GHz . Ormai con il solo die shrink sembra che non si possa aumentare le prestazioni del singolo core (con i 32 nm il turbo core è passato da 3,4 a 3,73GHz con nehalem), ma non è detto che le cose non sia destinate a cambiare il prossimo anno per Intel in concomitanza con la messa in produzione dei primi chip a 10nm. Chissà magari GF farà un processo produttivo straordinario, tanto da capovolgere la situazione che si è venuta a creare con i 32nm (imho i 28nm bulk per quanto non pensati per la sezione x86 di kaveri è un ottimo pp). Sembra che più si va giù con la miniaturizzazione più le differenze si fanno sottili, Forse è per tale motivo che AMD è fiduciosa con Zen? 10, 14, 16 o 20nm, potrebbero influenzare le prestazioni e i consumi molto meno di quello che si è soliti pensare. PS il monopolio del silicio negli integrati è destinato a finire tra meno di 5 anni. edit il i7 6700k consuma tanto per colpa della mobo o la causa è da imputare ai 500 MHz in più rispetto al i5 6600k? il delta è di 47W.. Ultima modifica di tuttodigitale : 07-08-2015 alle 00:10. |
|
|
|
|
|
07-08-2015, 09:03
|
#30057 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30315
|
Però lo sviluppo dell'architettura è comunque legato parecchio a quello che può concedere il silicio.
Ad esempio, da Zambesi a Piledriver, l'incremento si è avuto ma come è stato ottenuto? Con la gestione dei clock si è guadagnato un +11,11% di frequenza def, a fronte di un incremento di IPC del 5/7% poi da valutare se parzializzato per rimanere in un determinato IPC Kaveri con Steamroller ha pagato il silicio, visto che il 28nm Bulk anche se migliore del 32nm SOI sotto i 45W, ha di fatto segato la commercializzazione FX/Opteron e comunque castrato anche modelli mobili/desktop sulle potenze massime. Obbligando la scelta alle librerie ad alta densità, con ovvie limitazioni al raggiungimento di frequenze massime. Carrizo con Excavator da quello che ho letto introduce tutta una serie di features tutte indirizzate a cercare di limitare il più possibile i consumi per poi sfruttare il TDP di margine per aumentare le prestazioni, il tutto aggravato dalla compatibilità HSA 1.0 che comunque richiede transistor. Per me è evidente che AMD abbia come minimo frazionato la potenza di sviluppo architettura destinando parte delle risorse per cercare soluzioni in grado di sopperire al deficit del silicio. Nessuno nega che Intel sia molto più efficiente in forza bruta e nel prestazioni/consumo, ma guardare un Kaveri ed il prox Carrizo entrambi sul 28nm con equivalenti Intel anche con miniaturizzazione ben più spinta, da uno scenario ben differente rispetto a quello del confronto tra un 8350 ed un 5960X, ben differente dal 10/20% di IPC tra Piledriver/Steamroller/Excavator con impietoso -50% di prestazioni a parità di consumi tra 8350 e 5960X. SE AMD avrà a disposizione un 14/16nm per ZEN, e sembra comunque che lo avrà, poco importerà se mediocre/buono o ottimo, perché in ogni caso il margine di guadagnò in TDP dovrebbe essere notevole. A me basterebbe anche un pareggio prestazioni/consumo simile a quello del 22nm Intel, perché ciò vorrebbe dire (almeno) un posizionamento con i 95W Zen prossimo agli i7 => X6, fermo restando la valutazione tra forza bruta/potenza complessiva a die.
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M |
|
|
|
|
07-08-2015, 17:58
|
#30058 | |
|
Bannato
Iscritto dal: Jun 2011
Città: Forlì
Messaggi: 8199
|
Quote:
Scusate l'OT ma si vede benissimo che intel non è riuscita come gli altri anni con la fase di tock a migliorare così tanto proprio per il pp. E l'oc è circa identico ad haswell refresh a 22 nm per cui.... E con i 10 ci saranno altri problemi visto che hanno già cancellato cannolake (die shrink di skylake a 10) per kaby lake ancora a 14nm (stavolta non hanno usato l'aggettivo refresh ma non è altro che uno skylake refresh). Purtroppo mi sa che è il proccesso bulk ad avere più problemi con il passaggio a nanometrie inferiori visto che il leakage è sempre più alto di un processo SOI. Peccato che gf abbia cannato i 32 nm SOI e non abbia voluto continuare lo sviluppo come invece sta facendo ST con gli FD-SOI o IBM con PD-SOI e ET-SOI (che dovrebbe essere la stessa versione finfet del PD-SOI se non sbaglio). In generale tutti faticano ma quelli messi peggio per me sono i processi bulk caraterizzati da maggiore leakage Ultima modifica di Mister D : 07-08-2015 alle 18:01. |
|
|
|
|
|
07-08-2015, 20:55
|
#30059 | |||||
|
Senior Member
Iscritto dal: Sep 2010
Messaggi: 4087
|
Quote:
http://www.bitsandchips.it/enterpris...-e-bulk-finfet Quote:
Quote:
L'OC circa identico ai 22-32nm, non è poi così male, considerando che in giro processi produttivi che fanno meglio non ce ne sono (tranne il fd-soi 20nm, ammesso che venga prodotto qualcosa) Quote:
Quote:
PS Intel non ha rispettato la tabella di marcia, è vero, ma la concorrenza quando avrà un processo produttivo minimamente paragonabile? Tra 12 mesi? E saranno buoni come i 14nm attuali? E nel frattempo Intel resterà a guardare? |
|||||
|
|
|
|
07-08-2015, 21:12
|
#30060 | |
|
Bannato
Iscritto dal: Jun 2011
Città: Forlì
Messaggi: 8199
|
Quote:
il mio discorso non voleva dire o far intendere che gf o altri hanno al momento un processo produttivo migliore di quello intel. Ho solo detto e motivato che questo è il pp più problematico che intel abbia mai avuto nella storia recente e lo dimostra quello che tu stesso dici: per rientrare nei costi gli allungheranno la vita necessariamente oltre a quello previsto. Che poi di quanto lo sanno solo loro e dipenderà principalmente dalle problematiche del futuro 10 nm. Intel il prossimo anno resterà a guardare evolvendo ancora i 14 nm migliorandolo dove si può e così produrrà kabylake. GF ancora non si sa cosa produrra oltre i 14 nm bulk finfet di derivazione samsung e i 22 FD-SOI di derivazione ST. Potrebbe preparare anche un 22 PD-SOI visto che già lo deve produrre per IBM e il suo power8. O forse aspetterà i 14 ET-SOI o i 10 sempre by IBM. AMD infatti non ha specificato se saranno 14 di GF o i 16 di TMSC ma solo che sarà un pp FINFET. Chi gli darà le migliori garanzie verrà scelto ed è la prima volta che almeno amd avrà una scelta. Per quanto riguarda il costo soi vs bulk forse ti sei perso questo: http://www.bitsandchips.it/enterpris...dx-22nm-fd-soi Il pp prodotto da gf di derivazione ST si propone innanzitutto per essere economico al punto di costare quanto un pp 28 bulk ma offrendo prestazioni pari ai 14/16 finfet bulk. Ultima modifica di Mister D : 07-08-2015 alle 21:21. |
|
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 03:53.
















