





|
|||||||


|


_L.jpg)
|
|
 |
|
|
Strumenti |
 30-09-2009, 12:32
30-09-2009, 12:32
|
#1 |
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24165
|
[Thread Ufficiale] Aspettando Bulldozer *leggere prima pagina con attenzione*
[Thread Ufficiale] CPU serie FX AMD "Bulldozer"  Aspettando AMD "Piledriver"  (CPU a 32nm SOI) Premessa. Questo Thread ha lo scopo primario di raccogliere notizie e indiscrezioni sulle nuove CPU con architettura Bulldozer e CPU Piledriver (Bulldozer di seconda generazione) con tecnologia produttiva a 32nm SOI HKMG. Il [Thread Ufficiale] AMD APU Llano (Desktop) e aspettando Trinity - Krishna/Wichita lo provate a questo indirizzo! Il thread ufficiale su Zacate/Ontario, APU a 40nm Bulk, lo provate a questo indirizzo! Per cercare di avere ordine il thread sarà diviso in 6 pagine ognuna dedicata dal riassunto di uno specifico argomento. Indice del thread Prima Pagina: Premessa, indice e regolamento del Thread Seconda Pagina Caratteristiche Architettura AMD Bulldozer Terza Pagina Modelli attualmente/prossimamente in commercio Quarta Pagina Notizie dalla rete Quinta Pagina Link recensioni CPU serie FX dalla rete Sesta Pagina Approfondimento su Bulldozer/Piledriver Settima Pagina Post di servizio Regolamento * non sono ammessi notizie o commenti sull'andamento finanziario ( compreso i titoli quotati in borsa ) o di mercato da parte di AMD e/o Intel. * non sono ammessi commenti catastrofici o comunque in grado di generare FLAME * non sono graditi commenti stile Fanboy sia da parte AMD sia da parte Intel * non sono ammessi post stile "consigli per gli acquisti"; in pratica niente consigli o suggerimenti per la scelta di un nuovo hardware * non sono ammessi discussioni sulle CPU K8/K9 Athlon64/X2 * Le discussioni sull'architettura K10 sarà consentita solo per confronti diretti o di paragone sulle prestazioni o differenze architetturali * Cerchiamo di limitare al minimo gli argomenti OT, se proprio non ce la fate comunicate attraverso i messaggi privati * Per evitare di appesantire eccessivamente il Thread le immagini postate non dovranno superare la risoluzione 800X600 pixel  Per evitare che i post OT e AMD vs Intel inquinino il Thread ricordo che il moderatore di sezione "gianni1879" vigila continuamente sull'andamento del thread; ogni grave violazione del regolamento del Thread e del forum saranno "segnalati" con possibili e probabili sanzioni più o meno gravi.
__________________
AMD Ryzen 5600X|Thermalright Macho Rev. B|Gigabyte B550M AORUS PRO-P|2x16GB G.Skill F4-3200C16D-32GIS Aegis @ 3200Mhz|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Silicon Power A60 2TB + 1 SSD Crucial MX500 1TB (Games)|1 HDD SEAGATE IronWolf 2TB|Sapphire【RX6600 PULSE】8GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case In Win 509|Fans By Noctua|¦ Ultima modifica di capitan_crasy : 13-10-2011 alle 16:35. |

|
|
30-09-2009, 12:33
|
#2 |
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24165
|
Caratteristiche Architettura AMD Bulldozer
Caratteristiche Architettura AMD Bulldozer
Nuova architettura CPU di AMD, la quale andrà a sostituire l'attuale Tecnologia "Hammer" dove si basano gli attuali K8/K9/K10. Un po di storia L'architettura Bulldozer è stata progettata completamente da zero, a differenza di quanto avvenuto con Barcelona e Shanghai che rappresentano evoluzioni dell'architettura K8. L'annuncio fu dato prima ancora che il K10 fosse presentato ufficialmente, ma questo non era una assoluta novità per AMD. Il progetto originario del primo Bulldozer prevedeva una CPU a 4/6 core sul processo produttivo a 45nm SOI con supporto alle SSE5. L'uscita prevista era stata annunciata per fine 2009 dallo stesso neo CEO AMD Dirk Meyer e il suo concorrente diretto era l'architettura Nehalem di Intel. Purtroppo dopo i primi risultati da laboratorio sui primi sample, AMD decise la cancellazione della versione a 45nm SOI per passare direttamente al processo produttivo a 32nm SOI con importanti cambi architetturali, quali l'abbandono delle istruzioni SSE5 e l'adozione delle AVX di Intel. Non sapremo mai cosa andò storto, tuttavia la tecnologia low-k presente del Six core K10 AMD è cugina del lavoro svolto su Bulldozer a 45nm SOI. Bulldozer in dettaglio L'architettura Bulldozer prevede due core per elaborazioni Integer, affiancati da un'unità Floating Point che è condivisa. La scelta di AMD è quella di raddoppiare la sola parte Integer delle proprie CPU, lasciando condivisa quella Floating Point, dato che la maggior parte del calcolo riguarda proprio le unità Integer (in media per l'80%). Questo tipo di filosofia architetturale ha l'obbiettivo di ottenere il miglior rapporto tra prestazioni e consumo duplicando la parte Integer, massimizzando quindi il parallelismo delle operazioni e lasciando unificata un'unità in virgola mobile la quale avrà al suo attivo una notevole potenza di calcolo. Le caratteristiche della Floating Point per ogni modulo Bulldozer prevede due unità Multiply and Accumulate a 128 bit, a monte delle quali troviamo anche uno scheduler in virgola mobile; mentre per quanto riguarda le ISA sono supportate tutte le principali istruzioni (tranne le 3DNow) quali SSE3, SSE 4.1 and 4.2, AVX, AES, FMA4, XOP, PCLMULQDQ. La principale novità sono le istruzioni AVX (Advanced Vector eXtensions) a 256bit; lo sfruttamento di queste istruzioni verrà compiuto da Bulldozer mettendo in parallelo le due unità Floating Point a 128bit la quale, dal tipo di applicazione in esecuzione, possono essere configurate anche come 4x64bit, 2x128bit e 1x256bit. Altra novità importante e il nuovo decoder a 4 vie, completamente ridisegnato rispetto al tradizionale 3 vie adottato da AMD nelle ultime precedenti architetture (al K7 in su); la conseguenza diretta e che ora si può unire istruzioni branch x86 aumentando l'ampiezza del decoder. Sono anche presenti 3 distinti scheduler divise per le due unità Integer e uno per il Floating Point. Ogni unità Integer è dotata di una cache L1 per i dati da 16KB, valore inferiore ai 64KB integrati per ogni core nell'architettura K10, a monte dell'unità di fetch troviamo una seconda cache L1 da 64KB a 2 vie per istruzioni. AMD, rispetto al K10, ha allungato la pipeline interna alle unità di calcolo Integer in modo da ottenere frequenze di clock più elevate rispetto alle sue "vecchie" architetture. La scelta di questa soluzione però potrebbe provocare un eccessiva dipendenza dalle unità di branch prediction; AMD quindi ha integrato il Branch Prediction e il Fetch Logic facendoli operare in modo indipendente l'una dall'altra, evitando spiacevoli situazioni di stallo quando una di queste si arresti per un qualsiasi motivo. Un'unità di prefetch così aggressiva accoppiata a una pipeline più lunga, richiedono maggiori prestazioni (in termini di banda) per quanto riguarda il memory controller integrato; per il momento AMD non ha rilasciato le caratteristiche di questo componente, anche se ha confermato il suo totale ridisegno per fruttare al massimo la banda messa a disposizione dalle memorie RAM DDR3. Non si conosce quali frequenze possa gestire il controller RAM, tuttavia è ipotizzabile che possa adottare configurazioni superiori agli attuali Dual channer presenti nei controller Ram dei K10. La quantità della cache L2 (16 vie) dovrebbe essere da 2MB (valore non confermato ufficialmente da AMD) la quale sarà unificata tra i 2 core per modulo; ci sarà una anche una cache L3 verosimilmenteda 8MB (valore non confermato ufficialmente da AMD) condivisa anch'essa da tutti i moduli/core. AMD con Bulldozer, al contrario di Intel con la tecnologia HyperThreading o l'SMT (Simultaneous Multi Threading) che esegue per ogni core due threads in parallelo, ha scelto di integrare due unità di calcolo Integer complete affiancate da una complessa unità in virgola mobile che è condivisa.  Bulldozer di fatto integra due core che condividono le risorse di elaborazione in virgola mobile, avendo pipeline dedicate per quelle Integer AMD ha scelto la via della condivisione delle risorse, creata in modo tale da ottimizzare le prestazioni al consumo massimo ottenibile; non a caso si prevede che la presenza della sola seconda unità di calcolo Integer all'interno di ogni modulo Bulldozer, implichi un incremento della superficie complessiva del chip pari al 12%, valore particolarmente contenuto considerando il boost prestazionale ottenibile. Sul capitolo consumi Bulldozer con i suoi moduli, potrà gestire dinamicamente e indipendentemente l'uno dall'altro il Vcore e frequenza di clock, anche se questo non può essere fatto per singolo core ma solo per coppia di core legato comunque al modulo Bulldozer. Novità in vista anche per il Turbo Core AMD, introdotto con i K10 step E, la quale si dovrebbe avvicinare molto a quella Turbo Boost introdotta da Intel con le CPU della famiglia Nehalem. Il socket AM3r2 o AM3+ AMD ha confermato l'uscita di un (nuovo?) socket chiamato molto genericamente AM3r2 o AM3+. Al momento ci sono poche informazioni ma quello sicuro è che le CPU Bulldozer non saranno compatibili con gli attuali e future schede madri socket AM3. La causa è da imputare ad un cambio radicale legate alla circuiteria di alimentazione; la stessa AMD ha dichiarato che adattare Bulldozer sugli attuali socket AM3 avrebbe portato ad un aumento dei costi finali e la impossibilità di utilizzare tutte le nuove caratteristiche della nuova architettura limitando eccessivamente le prestazioni finali. Resta da confermare la compatibilità dei socket AM3+ sulle attuali CPU K10 socket AM3 attualmente presenti sul mercato. Piattaforma AMD "Scorpius" Con l'uscita delle CPU Bulldozer AMD presenterà una nuova piattaforma chiamata "Scorpius", la quale sarà composta da nuovi chipset AMD serie 900 modello 990FX, 990X (Crossfire ready) e 970. Ci saranno anche dei nuovi southbridge serie 900, in particolare il modello Hudson D3 sarà in grado di supportare 4 porte USB 3.0 senza l'aiuto di chip esterni.  Le prime soluzioni della famiglia Bulldozer sono attese al debutto nella prima parte del 2011 e saranno costruite da GlobalFoundries con il processo produttivo a 32nm SOI. Le prime cpu della famiglia Bulldozer che vedremo sul mercato con tutta probabilità saranno quelle della famiglia Opteron, con versioni 6/8/12 e 16 core. Le versioni desktop della famiglia Zambezi sono attesi subito dopo con modelli 4/(forse)6 e 8 core. AMD ha comunicato che Bulldozer sarà pronto nella prima parte del 2011.  
__________________
AMD Ryzen 5600X|Thermalright Macho Rev. B|Gigabyte B550M AORUS PRO-P|2x16GB G.Skill F4-3200C16D-32GIS Aegis @ 3200Mhz|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Silicon Power A60 2TB + 1 SSD Crucial MX500 1TB (Games)|1 HDD SEAGATE IronWolf 2TB|Sapphire【RX6600 PULSE】8GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case In Win 509|Fans By Noctua|¦ Ultima modifica di capitan_crasy : 24-10-2010 alle 10:23. |
|
|
|
30-09-2009, 12:34
|
#3 |
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24165
|
Caratteristiche Tecnologia AMD Fusion
Perchè integrare CPU e GPU in un unico elemento
Integrazione tra GPU e CPU: è questa la principale evoluzione tecnologica che AMD e ATI si aspettano di presentare al mercato nei prossimi anni. Il nome scelto per i prodotti che integreranno GPU e CPU è quello di Fusion, che ben simboleggia l'unione tra architetture sulla carta e di fatto molto differenti tra di loro. La risultante saranno una serie di prodotti sviluppati per svariati ambiti di impiego, nei quali quindi la combinazione tra parte CPU classica e parte GPU assumerà pesi differenti tra di loro. Per quale motivo si vuole giungere a fornire soluzioni che integrino al proprio interno una GPU? La principale giustificazione è legata all'elevata potenza elaborativa di cui sono capaci le GPU, in termini di Gflops, rispetto a quanto accessibile con una CPU. Merito di questo risultato è l'innata capacità delle GPU di eseguire un gran numero di elaborazioni parallele, richieste per la generazione delle scene 3D. Sfruttando un'analogia, una CPU opera come un aereo da combattimento, estremamente veloce ma in grado di trasportare solo due persone contemporaneamente; una GPU è invece paragonabile ad un aereo di linea, meno veloce in assoluto ma capace di trasportare molte più persone e quindi di svolgere complessivamente più lavoro. Le GPU hanno una potenza di elaborazione massima teorica estremamente elevata, sintetizzata dai Gflops che possono processare; si tratta tuttavia di una capacità per molti versi vincolata, che può essere sfruttata solo con quelle applicazioni che richiedono l'elaborazione di un elevato numero di dati in parallelo. Per questo motivo gli ambiti di utilizzo delle GPU in elaborazioni non grafiche di calcolo generale, o più semplicemente GP-GPU, sono limitati ad alcune tipologie di elaborazione; è evidente come nel corso dei prossimi anni gli sviluppatori software, grazie all'introduzione delle OpenCL e anche alla disponibilità di GPU sempre più complesse oltre che potenti e estremamente programmabili, potranno operare ad una nuova tipologia di software dove la GPU si prenda in carico i calcoli più pesanti in modo da eseguire operazioni in minor tempo possibile. 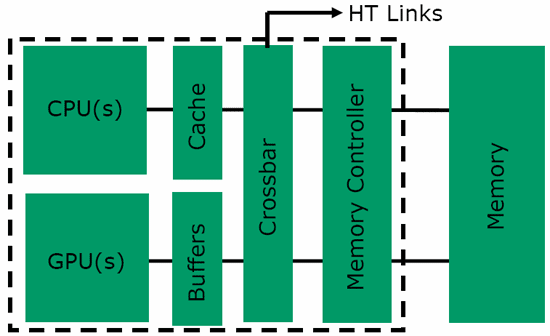 Un pò di storia In un intervista al vice presidente esecutivo AMD Henri Richard vengono svelati alcuni dettagli sulla tecnologia AMD Fusion. "Penso che "Fusion" sia un processo evolutivo, piuttosto che una fusione" In poche parole AMD pensa a questo progetto come un vero e proprio processo evolutivo delle attuali CPU. Il primo tentativo in assoluto fu la creazione di un Dual core nativo K10 senza cache L3 a 45nm SOI la quale sarebbe stato accoppiato sullo stesso package una IGP della serie RV620 (cioè la stessa degli attuali chipset AMD 785G/880G) costruita a 55nm bulk; lo stile costruttivo era lo stesso dei processori Intel core Clarkdale. Il progetto fu accantonato per problemi logistici legati alle differenti tecnologie costruttive dei due chip principali (CPU IBM SOI e GPU TSMC bulk); così il primo progetto Fusion fu cancellalo ma AMD come eredità rilasciò sul mercato il K10 Dual core nativo con il nome di Athlon2 core Regor. APU Llano: il futuro di AMD! 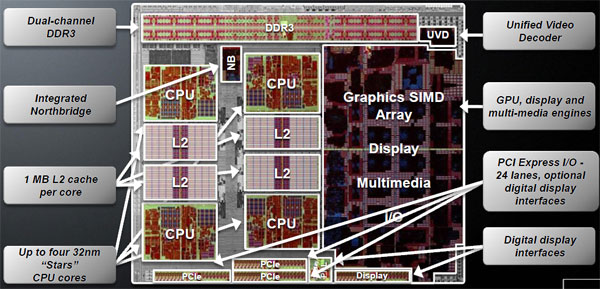 AMD passò quindi allo scenario più complesso cioè un unico componente di silicio nel quale i transistor della parte CPU sono integrati con quelli della parte GPU e viceversa con tecnologia costruttiva a 32nm SOI. APU (Accelerated Processing Unit) Llano sarà composto da core X86 derivanti dall'architettura K10 e una GPU DX11 costruiti e prodotti entrambi a 32nm con tecnologia SOI provenienti da Globalfoundries; questa soluzione rappresenterà la prima GPU ATI costruita con la tecnologia SOI di IBM. Ciascuno dei core x86 implementati nella APU avrà una superficie complessive molto contenuta, pari a 9,69 millimetri quadrati, per un totale di poco più di 35 milioni di transistor; da questo conteggio è esclusa la cache L2 da 1 Mbyte, indipendente per ciascuno dei core. AMD dichiara un range di consumo variabile da un minimo di 2,5 Watt sino a 25 Watt per ciascuno dei core: questo significa, con tutta probabilità, che sarà possibile vedere sul mercato versioni di APU con valori di TDP molto diversi tra loro. Grazie a alcune precise strategie di design, la APU introduce la modalità Package C6, la quale permette di diminuire l'alimentazione sull'intera struttura compresa la GPU e modulo UVD. L'introduzione di tale modalità permette a ogni singolo core X86 di venir spento, anche il core grafico può essere completamente spento, mentre il consumo del controller RAM per la componente grafica può essere gestito dinamicamente. Per ottenere tutto questo AMD ha implementato una singola linea di alimentazione VDDNB condivisa tra GPU, UVD, controller memoria grafico e northbridge; con questa è possibile gestire dinamicamente sia la tensione sia la frequenza di clock, con il primo elemento che viene selezionato in funzione dello stato nel quale si trovano questi componenti. Ulteriore ottimizzazione al consumo dell'intero sistema è implementata con la tecnologia adaptive backlight modulation; in pratica l'immagine riprodotta a schermo viene analizzata in modo da ridurre gradualmente l'intensità della backlight incrementando la luminosità dei pixel, riducendo il consumo complessivo dello schermo senza che questo porti ad una variazione percepibile da parte dell'utente della luminosità complessiva dell'immagine a video. Per metà 2012 AMD utilizzerà l'architettura Bulldozer di seconda generazione per le future soluzioni APU denominate "Trinity"; questo avverrà, con tutta probabilità nel corso del 2012. 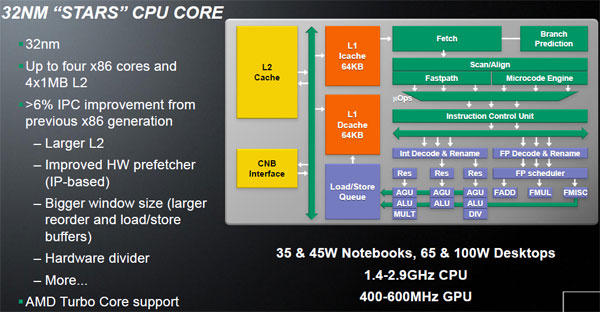 Piattaforma AMD "Linx"  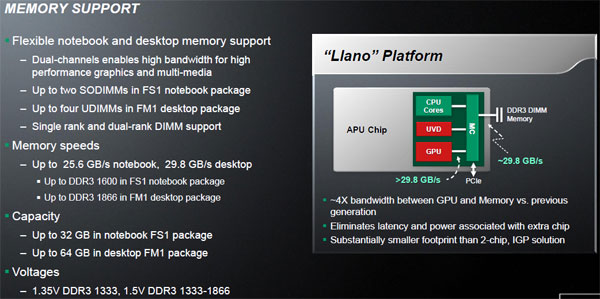 A partire dal 2011 AMD, per il mercato mainstream, presenterà la piattaforma "Linx" dove ci saranno le prime APU basate sulla tecnologia FUSION. La APU sarà basata su 4 core X86-x64 AMD derivanti dall'architettura "Stars" o più comunemente chiamata K10; il modello di riferimento è il core Propus, naturalmente riveduto e corretto grazie anche al processo produttivo a 32nm SOI. Llano avrà una cache L2 da 1MB per core X86, mentre la cache L3 sarà assente. La GPU integrata nello stesso pezzo di silicio, dovrebbe avere 400/320 stream processors divisi in 6/5 SIMD engines con una capacità di calcolo massima classe; questa modello di APU avrà circa un 1 miliardo di transistor. "Gigaflops"; CPU e GPU condivideranno lo stesso controller di memoria DDR3 con una frequenza massima massima di 1866Mhz. La nuova APU non avrà bisogno di alcun chipset o Northbridge tradizionale in quanto tale elemento sarà integrato; per quanto riguarda il Southbridge AMD presenterà la nuova serie Hudson; in particolare la versione Hudson M/D3 sarà il prima a supportare lo standard USB 3.0.  Lista modelli Socket FM1 ☆A8-Series Socket FM1☆ 32nm SOI Quad core Core Llano Step B0 GPU DX11 cache L2 1MB x 4 Memoria supportata Dual channel DDR3 ・A8-3850 - HD6550D・ Frequenza di clock 2.90Ghz Frequenza Turbo Core Assente Stream Processor GPU 400 Frequenza di clock GPU 600Mhz Memorie Supportate Dual channel DDR3-1333-1600-1866Mhz TDP 100W ・A8-3800 - HD6550D・ Frequenza di clock 2.40Ghz Frequenza Turbo Core 2.70Ghz Stream Processor GPU 400 Frequenza di clock GPU 600Mhz Memorie Supportate Dual channel DDR3-1333-1600-1866Mhz TDP 65W ☆A6-Series Socket FM1☆ 32nm SOI Quad core Core Llano Step B0 GPU DX11 cache L2 1MB x 4 Memoria supportata Dual channel DDR3 ・A6-3650 - HD6530D・ Frequenza di clock 2.60Ghz Frequenza Turbo Core Assente Stream Processor GPU 320 Frequenza di clock GPU 443Mhz Memorie Supportate Dual channel DDR3-1333-1600-1866Mhz TDP 100W ・A6-3600 - HD6530D・ Frequenza di clock 2.10Ghz Frequenza Turbo Core 2.40Ghz Stream Processor GPU 320 Frequenza di clock GPU 443Mhz Memorie Supportate Dual channel DDR3-1333-1600-1866Mhz TDP 65W Piattaforma AMD "Sabine"  Per il mercato Mobile AMD presenterà la piattaforma "Sabine". La APU "Llano" in versione mobile sarà presumibilmente uguale alla versione Desktop, quindi con 4 core X86-x64 AMD K10 con L2 da 1MB senza cache L3; la GPU dovrebbe avere circa 400/480 stream processors con una capacità di calcolo massima classe "Gigaflops"; CPU e GPU condivideranno lo stesso controller di memoria DDR3. Anche in questo caso la APU non avrà bisogno di alcun chipset o Northbridge tradizionale in quanto tale elemento sarà integrato; per quanto riguarda il Southbridge AMD presenterà la nuova serie SB900 la quale la versione Hudson M/D3 sarà il prima a supportare lo standard USB 3.0. ☆A8-Series Socket FS1☆ 32nm SOI Quad core Core ??? GPU DX11 Step ?? cache L2 1MB x 4 Memoria supportata Dual channel DDR3/DDR3L ・A8-3530MX - HD6620G・ Frequenza di clock 1.90Ghz Frequenza Turbo Core 2.60Ghz Stream Processor GPU 400 Frequenza di clock GPU 444Mhz Memorie Supportate Dual channel DDR3-1333-1600Mhz/DDR3L-800-1066-1333Mhz TDP 45W ・A8-3510MX - HD6620G・ Frequenza di clock 1.80Ghz Frequenza Turbo Core 2.0 2.50Ghz Stream Processor GPU 400 Frequenza di clock GPU 444Mhz Memorie Supportate Dual channel DDR3-1333-1600Mhz/DDR3L-800-1066-1333Mhz TDP 45W ・A8-3500MX - HD6620G・ Frequenza di clock 1.50Ghz Frequenza Turbo Core 2.40Ghz Stream Processor GPU 400 Frequenza di clock GPU 444Mhz Memorie Supportate Dual channel DDR3-1066Mhz-1333Mhz/DDR3L-800-1066-1333Mhz TDP 35W ☆A6-Series Socket FS1☆ 32nm SOI Quad core Core ??? GPU DX11 Step B? cache L2 1MB x 4 Memoria supportata Dual channel DDR3/DDR3L ・A6-3410MX - HD6520G・ Frequenza di clock 1.60Ghz Frequenza Turbo Core 2.30Ghz Stream Processor GPU 320 Frequenza di clock GPU 400Mhz Memorie Supportate Dual channel DDR3-1333-1600Mhz/DDR3L-800-1066-1333Mhz TDP 45W ・A6-3400MX - HD6520G・ Frequenza di clock 1.40Ghz Frequenza Turbo Core 2.30Ghz Stream Processor GPU 320 Frequenza di clock GPU 400Mhz Memorie Supportate Dual channel DDR3-1066-1333Mhz/DDR3L-800-1066-1333Mhz TDP 35W ☆A4-Series Socket FS1☆ 32nm SOI Dual core Core ??? GPU DX11 Step B? cache L2 1MB x 2 Memoria supportata Dual channel DDR3/DDR3L ・A4-3310MX - HD6480G・ Frequenza di clock 2.10Ghz Frequenza Turbo Core 2.50Ghz Stream Processor GPU 240 Frequenza di clock GPU 444Mhz Memorie Supportate Dual channel DDR3-1066Mhz-1333Mhz/DDR3L-800-1066-1333Mhz TDP 45W ・A4-3300M - HD6480G・ Frequenza di clock 1.90Ghz Frequenza Turbo Core 2.50Ghz Stream Processor GPU 240 Frequenza di clock GPU 444Mhz Memorie Supportate Dual channel DDR3-1066Mhz-1333-1600Mhz/DDR3L-800-1066-1333Mhz TDP 35W ☆E2-Series Socket FS1☆ 32nm SOI Dual core Core ??? GPU DX11 Step B? cache L2 1MB x 2 Memoria supportata Dual channel DDR3/DDR3L ・E2-3000M - HD6380G・ Frequenza di clock 1.80Ghz Frequenza Turbo Core 2.40Ghz Stream Processor GPU 160 Frequenza di clock GPU 400Mhz Memorie Supportate Dual channel DDR3-1066Mhz-1333Mhz/DDR3L-800-1066-1333Mhz TDP 35W Architettura "Bobcat"  Abbiamo visto come AMD per Llano abbia adattato una GPU ATI costruita con tecnologia bulk alla tecnologia SOI di IBM; per quest'altra APU AMD ha studiato il processo inverso. In pratica ha adattato dei core X86 AMD utilizzando tecnologia produttiva bulk wafer TSMC con lo scopo di creare una CPU senza la tecnologia SOI di IBM, in modo da adattare i due componenti (CPU AMD e GPU ATI) in un unica catena produttiva. Tale soluzione verrà utilizzata per la piattaforma "Brazus", composta da un APU con core X86 derivanti da una nuova architettura denominata "Bobcat" e una GPU DX11, costruiti entrambi con silicio 40nm bulk provenienti dalla fonderia TSMC; questa nuova soluzione andrà nello stesso mercato delle CPU ATOM di Intel. "Bobcat" è il nome dell'architettura X86 studiata per i sistemi a basso consumo, dove attualmente vede le CPU Atom come leader. Il primo elemento distintivo dell'architettura Bobcat è la possibilità di operare con un livello di consumo inferiore a 1 Watt con alcune specifiche versioni A differenza di Atom, Bobcat è un architettura di tipo out of order, comune alla maggior parte dei moderni processori x86, questa soluzione permette di ottenere migliori prestazioni grazie alla possibilità del processore di riorganizzare le istruzioni in modo tale che la loro esecuzione sia la più efficiente possibile in termini di prestazioni velocistiche. L'altra faccia della medaglia è un certo dazio da pagare in termini di consumi massimi; tuttavia Bobcat dovrebbe essere l'ideale tra consumi, ridotte dimensioni e potenza elaborativa di una cpu x86 moderna. L'architettura di Bobcat utilizza un design Dual issue, con due pipeline a 15 fasi contro le 16 fasi nell'architettura Atom. L'ago delle prestazioni rimane a favore di Bobcat grazie al design out of order, la quale permetterà di avere livelli prestazionali, a parità di clock, ben più elevati delle soluzioni Atom su applicazioni single threaded; Bobcat supporta i set di istruzioni SSE sino alla release 3 comprese le tecnologie di virtualizzazione. Per quanto riguarda la cache L1 sarà in due blocchi da 32KB ciascuno, rispettivamente per dati e istruzioni, del tipo associativa a 8 vie con latenza di 3 cicli di clock. La cache L2 sarà di 512KB a 16 vie, con latenza di 17 cicli di clock. I core X86 di Bobcat verrà utilizzato nelle prime soluzioni APU della famiglia Fusion, la GPU dovrebbe avere circa 80 stream processors cioè paragonabile più o meno alla GPU HD5450; anche in questo caso CPU e GPU condivideranno lo stesso controller di memoria DDR3. Per economizzare al massimo i consumi AMD ha implementato le tecnologie clock gating, power gating e states di tipo low power; quest'ultimo consente di abbassare al massimo il livello di consumo in idle. A completare le funzionalità una serie di innovazioni micro architetturali che riducono al minimo i trasferimenti di dati interni al chip, oltre a ridurre il numero di loro letture allo stretto indispensabile. AMD non ha fornito informazioni ufficiali sul memory controller DDR3, tuttavia alcune voci parlano di un supporto massimo alle DDR3 1333Mhz a basso consumo; il controller RAM verrà condiviso tra i core X86 e GPU. Bobcat troverà spazio nelle soluzioni APU Ontario, costruite con tecnologia produttiva a 40nm bulk prodotto da TSMC. L'uscita di Ontario è prevista per i primi mesi del 2011. Piattaforma "Brazos" Attesa per il 2011 la piattaforma "Brazos" sarà composto da CPU con core "Ontario" costituito dall'architettura X86 "Bobcat" in configurazione single/dual core e una GPU DX11; il valore TDP può variare tra i 9W e i 18W a secondo dei modelli. Ci sarà anche una versione desktop a basso consumo chiamata “Zacate” la qualè riprende tutte le caratteristiche sia di TDP sia di core, GPU della piattaforma Brazos core Ontario. Entrambi le piattaforme avranno dei nuovi Southbridge serie SB900 modello Hudson M/D1 la quale potranno gestire porte SATA3 ma NON le USB 3.0. Il socket FT1 salta direttamente la APU alla scheda mamma quindi sarà impossibile cambiare la l'elemento in un secondo momento; tutte le APU sono vendute con la propria scheda mamma... Modelli attualmente in commercio! ☆E-Series Socket FT1☆ 40nm Bulk Core Zacate GPU DX11 Step ?? cache L2 512KB x 2 Memoria supportata Single channel DDR3/DDR3L-800-1066-1333Mhz ●AMD E-350 Dual core/HD6310 Frequenza di clock 1.60GHz Numero Stream processor GPU 80 (40+40) Frequenza di clock GPU 500Mhz TDP 18W ●AMD E-250 Single core/HD6310 Frequenza di clock 1.50GHz Numero Stream processor GPU 80 (40+40) Frequenza di clock GPU 500Mhz TDP 18W ☆C-Series Socket FT1☆ 40nm Bulk Core Ontario GPU DX11 cache L2 512KB x 2 Memoria supportata Single channel DDR3/DDR3L-800-1066-1333Mhz ●AMD C-50 Dual core/HD6250 Frequenza di clock 1.00GHz Numero Stream processor GPU 80 (40+40) Frequenza di clock GPU 280Mhz TDP 9W ●AMD C-30 Single core/HD6250 Frequenza di clock 1.20GHz Numero Stream processor GPU 80 (40+40) Frequenza di clock GPU 280Mhz TDP 9W
__________________
AMD Ryzen 5600X|Thermalright Macho Rev. B|Gigabyte B550M AORUS PRO-P|2x16GB G.Skill F4-3200C16D-32GIS Aegis @ 3200Mhz|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Silicon Power A60 2TB + 1 SSD Crucial MX500 1TB (Games)|1 HDD SEAGATE IronWolf 2TB|Sapphire【RX6600 PULSE】8GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case In Win 509|Fans By Noctua|¦ Ultima modifica di capitan_crasy : 30-06-2011 alle 16:26. |
|
|
|
30-09-2009, 12:35
|
#4 |
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24165
|
Notizie dalla rete
Raccorta delle notizie del "[Thread Ufficiale] Aspettando Bulldozer e Llano". (cliccare sulla scritta)Dal 28.08.2009 al 30.12.2010 02.01.2011 AMD Brazos anche nei tablet! Clicca qui... 03.01.2011 AMD mobile "Comal": L'erede di Sabine nel 2012! Clicca qui... 04.01.2011 Gigabyte GA-E350N-USB3: Piattaforma Brazos in dettaglio! Clicca qui... Ufficiale: AMD presenta la piattaforma Brazos! Clicca qui... 05.01.2011 990FX: Prime (fugaci) immagini made in MSI! Clicca qui... Piattaforma Brazos per Gigabyte, Asus e MSI! Clicca qui... HWiNFO32: In arrivo nuovi socket per Trinity? Clicca qui... 08.01.2011 Socket AM3+ a 942 pin, uno in più del socket AM3! Clicca qui... 12.01.2011 MSI 890FXA-GD65 compatibile con le CPU Socket AM3+? Clicca qui... 13.01.2011 GF su Llano: Tempi più brevi per la presentazione? Clicca qui... Zambezi più veloce del 50% sul i7 950/Phenom2 1100T? Clicca qui... 20.01.2011 Nuovi dettagli sui chipset AMD serie 900! Clicca qui... 21.01.2011 Hybridcrossfire Ready per Llano! Clicca qui.. 24.01.2011 Più 50% di Bulldozer: ecco la slide di riferimento! Clicca qui... 25.01.2011 Chipset serie 900 prima del previsto? Clicca qui... 28.01.2011 Review MSI E-350IA: APU E-350 alla prova! Clicca qui... 02.02.2011 Nuovi dettagli sulla tecnologia Turbo Core nelle CPU AMD Bulldozer Clicca qui... 04.02.2011 Versione Mobile di Llano anticipato a maggio? Clicca qui... 11.02.2011 Addio ai brand Phenom, Athlon e Sempron per BD e Llano? Clicca qui... 14.02.2011 In arrivo 890FX Deluxe5, la prima scheda mamma ASRock AM3+ con 890FX+SB850! Clicca qui... 15.02.2011 ASRock 890FX Deluxe5 (Bios UEFI) Socket AM3+ in foto! Clicca qui... 01.03.2011 16 Core Processor: Upgrade from AMD Opteron 6100 Series to Upcoming "Interlagos"! Clicca qui... AMD Fusion APU Llano in a Multi-Tasking Technology Demonstration! Clicca qui... MSI/ASrock: Schede mamme socket AM3+ in arrivo ad aprile! Clicca qui... Chipset 990FX con southbridge SB950 in foto! Clicca qui... 02.03.2011 AMD presenterà Bulldozer al E3 show il 7/9 Giugno? Clicca qui... 03.03.2011 Prime schede mamme AM3+ per Gigabyte! Clicca qui... 04.03.2011 Llano VS i7: Secondo video! Clicca qui... 06.03.2011 Nuove slide su Llano! Clicca qui... 07.03.2011 Nuova roadmap 2011/2012 sulle soluzioni Mobile AMD! Clicca qui... 08.03.2011 CPU Bulldozer a Giugno: Nuove conferme! (APU Llano Serie "A" a Luglio) Clicca qui... 10.03.2011 Gigabyte presenta 6 schede mamme socket AM3+! Clicca qui... 11.03.2011 ASRock 890GM Pro3 R2.0 AM3+ in Giappone! Clicca qui... 12.03.2011 I (presunti) loghi di Bulldozer!!! Clicca qui... 14.03.2011 Nuovi dettagli sui modelli Bulldozer in arrivo! Clicca qui... Nuove notizie sui modelli Bulldozer e Llano per il mercato desktop! Clicca qui... 16.03.2011 I modelli Llano socket FM1 per il mercato desktop! Clicca qui... 25.03.2011 Labview: Differenze tra ASRock 890FX Deluxe5 e ASRock 890FX Deluxe4! Clicca qui... 31.03.2011 Nvidia sblocca lo SLI sui chipset AMD serie 990FX e 990X! Clicca qui... 04.04.2011 Variazione negli accordi di fornitura tra AMD e GlobalFoundries Clicca qui... 05.04.2011 Schede madri Gigabyte con socket AM3+ Clicca qui... Soluzioni AMD Llano in consegna ai partner OEM Clicca qui... AMD, GlobalFoundries e gli accordi di fornitura: alcune considerazioni Clicca qui... 06.04.2011 CPU socket AM3+: anche MSI ne conferma la compatibilità Clicca qui... Gigabyte attacca gli hack di ASUS e MSI sul socket AM3! Clicca qui... Processori AMD Bulldozer: al debutto il 7 Giugno? Clicca qui... 11.04.2011 Nuove informazioni sulle soluzioni AMD Llano Clicca qui... Software Optimization Guide Per CPU Bulldozer: L'analisi di bjt2! Clicca qui... 14.04.2011 Processori Bulldozer su socket AM3? E' possibile Clicca qui... Un cambio di strategia per AMD Vision Clicca qui... 23.04.2011 Labview: Nuove differenze tra il socket AM3+ e il socket AM3! Clicca qui... Step A1 e Step B0: I primi step di Bulldozer! Clicca qui... 27.04.2011 Llano A8-3510MX Vs i7 2600 desktop: potenza di calcolo GPU a confronto! Clicca qui... 28.04.2011 AMD mostra il socket FM1 per Llano e una nuova roadmap! Clicca qui... 03.05.2011 Nuovi rumors sulle date di uscita di Bulldozer e Llano! Clicca qui... Primi prezzi di 3 schede mamme socket AM3+ con chipset 900 di MSI! Clicca qui... 04.05.2011 I primi bench di Bulldozer e Llano? Clicca qui... Prima immagine della Asus M5A99X Evo con chipset 990X! Clicca qui... 06.05.2011 Asus: Pronte 6 nuove schede mamme socket AM3+ e chipset 900! Clicca qui... 07.05.2011 Prima immagine di un scheda mamma socket FM1 (da laboratorio) per Llano! Clicca qui... 09.05.2011 Le possibili combinazioni del HybridCrossfire destinato alle APU Llano! Clicca qui... 14.05.2011 Nuove immagini del socket FM1! Clicca qui... Jetway HA13 con chipset 990X! Clicca qui... 15.05.2011 Primi prezzi delle schede MSI con chipset serie 900! Clicca qui... 19.05.2011 MSI 990FXA-GD80 in foto! Clicca qui... 21.05.2011 Gigabyte GA-990FXA-UD7 In foto! Clicca qui... 23.05.2011 Prime conferme sulle frequenze/TDP delle APU Llano per il mercato Mobile! Clicca qui... Prime foto delle soluzioni APU Llano per il mercato Mobile! Clicca qui... 24.05.2011 Ufficiale: I primi bench delle APU Llano per il mercato Mobile! Clicca qui... 25.05.2011 Prime Analisi del BIOS compatibile alle CPU 8 core Bulldozer by Labview! Clicca qui... 27.05.2011 Nuove slide su Llano! Clicca qui.. FX-8130P già in listino nel mercato cinese??? Clicca qui... 30.05.2011 AMD presenta i chipset serie 900! Clicca qui... 31.05.2011 Piattaforma "Colman" e "Deccan": le APU Mobile del 2012! Clicca qui... 01.06.2011 AMD smentisce se stessa (parte seconda): Bulldozer solo nel terzo trimestre 2011! Clicca qui... AMD: Bulldozer posticipato a tavolino unicamente per "favorire" le soluzioni Llano! Clicca qui... 02.06.2011 AMD conferma il 10 core "Komodo" per il mercato desktop entro il 2012! Clicca qui... 07.06.2011 Nuova roadmap sulle CPU Bulldozer! Clicca qui... AMD "Finalmente" mostra le CPU FX Bulldozer!!! Clicca qui... 08.06.2011 Rumors AMD (da prendere con le dovute cautele)! Clicca qui... 09.06.2011 Primi bench di Llano modello A8-3800! Clicca qui... 13.06.2011 AMD A8-3800 Llano APU & Gigabyte GA-A75-UD4H in video più Bench! Clicca qui... 14.06.2011 AMD presenta le APU Llano per il mercato Mobile! Clicca qui... Addio al socket AM3+ per le soluzioni "Komodo" nel 2012! Clicca qui... Nuove informazioni sul Turbo Core di Bulldozer! Clicca qui... 15.06.2011 AMD: +50% di GFLOPS per Trinity! Clicca qui... Preview Llano A8-3850 Desktop by AnandTech! Clicca qui... 20.06.2011 Revision Guide for AMD Family 12h Processors: Le analisi di bjt2! Clicca qui... 21.06.2011 Nuove informazioni su Bulldozer entro il 16 Luglio? Clicca qui... 22.06.2011 Gigabyte presenta le prime schede mamme FM1 e conferma lo step B0 per Llano! Clicca qui... 30.07.2001 AMD presenta la piattaforma Lynx composta da APU Llano per il mercato desktop! Clicca qui... Lista recensioni APU Llano Socket FM1! Clicca qui... 09.07.2011 Donanimhaber: Primi bench di un ES Bulldozer step B1, anzi NO!!! Clicca qui... 21.07.2011 Operation Scorpius – The Legend of FX Returns! Clicca qui... 24.07.2011 Prime conferme sulla data d'uscita e frequenze dei modelli Bulldozer Desktop! Clicca qui... 25.07.2011 Socket FM2 per Komodo e Trinity! Clicca qui... 27.07.2011 CPU Bulldozer posticipate (ancora) al quarto trimestre 2011? Clicca qui... 02.08.2011 AMD punta (a sorpresa) sui 28nm nel 2013 per il mercato Server! Clicca qui... 10.08.2011 Ufficiale: Gli opteron Bulldozer definitivi sono basati sugli step B2! Clicca qui... 16.08.2011 Primi codici OPN per i modelli FX-8150/FX-8120! Clicca qui... 31.08.2011  Gigabyte: Rilasciati i BIOS e le caratteristiche per le CPU FX!!! Clicca qui... 01.09.2011 Labview: Ecco i codici OPN delle CPU Bulldozer rilasciati da ASrock! Clicca qui... 21.09.2011 Donanimhaber: CPU AMD FX il 12 ottobre! Clicca qui... 24.11.2011 Donanimhaber: Slide finali delle CPU FX! Clicca qui... 26.09.2011 GlobalFoundries: Cancellati i 22nm, 20nm per il 2014! Clicca qui... 02.10.2011 Entro domani i BIOS definitivi per le CPU FX? Clicca qui... 03.10.2011 Donanimhaber: Piledriver anche su socket AM3+! Clicca qui...
__________________
AMD Ryzen 5600X|Thermalright Macho Rev. B|Gigabyte B550M AORUS PRO-P|2x16GB G.Skill F4-3200C16D-32GIS Aegis @ 3200Mhz|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Silicon Power A60 2TB + 1 SSD Crucial MX500 1TB (Games)|1 HDD SEAGATE IronWolf 2TB|Sapphire【RX6600 PULSE】8GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case In Win 509|Fans By Noctua|¦ Ultima modifica di capitan_crasy : 04-10-2011 alle 10:50. |
|
|
|
30-09-2009, 12:35
|
#5 | |||||||||
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24165
|
Approfondimento su Bulldozer/Fusion
Aggiornamento 28.08.2010
Quote:
Quote:
Quote:
Sandy Bridge Vs Bulldozer: il confronto di bjt2 Quote:
Quote:
Quote:
Aggiornamento 11/04/2011 Quote:
Revision Guide for AMD Family 12h Processors: Le analisi di bjt2! Quote:
__________________
AMD Ryzen 5600X|Thermalright Macho Rev. B|Gigabyte B550M AORUS PRO-P|2x16GB G.Skill F4-3200C16D-32GIS Aegis @ 3200Mhz|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Silicon Power A60 2TB + 1 SSD Crucial MX500 1TB (Games)|1 HDD SEAGATE IronWolf 2TB|Sapphire【RX6600 PULSE】8GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case In Win 509|Fans By Noctua|¦ Ultima modifica di capitan_crasy : 20-06-2011 alle 23:02. |
|||||||||
|
|


|
30-09-2009, 12:36
|
#6 |
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24165
|
FAQ e le possibile date di uscita
Le CPU serie FX-8000/FX-6000/FX-4000 con architettura Bulldozer dovrebbero essere presentati il 12 Ottobre 2011: Clicca qui... Le schede madri socket AM3+ con chipset AMD serie 900 sono attualmente in commercio! Le APU Llano per il mercato mobile sono attualmente in commercio! Le APU Ontario/Zacate sono attualmente in commercio! La piattaforma "Lynx" composta da APU Llano per il mercato desktop è attualmente in commercio! Le soluzioni Komodo (Bulldozer di seconda generazione) a 10/8/6 core sono attese per la prima parte del 2012! (data non confermata ufficialmente) 
__________________
AMD Ryzen 5600X|Thermalright Macho Rev. B|Gigabyte B550M AORUS PRO-P|2x16GB G.Skill F4-3200C16D-32GIS Aegis @ 3200Mhz|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Silicon Power A60 2TB + 1 SSD Crucial MX500 1TB (Games)|1 HDD SEAGATE IronWolf 2TB|Sapphire【RX6600 PULSE】8GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case In Win 509|Fans By Noctua|¦ Ultima modifica di capitan_crasy : 26-09-2011 alle 12:30. |
|
|
|
30-09-2009, 12:48
|
#7 |
|
Senior Member
Iscritto dal: May 2006
Città: Regione FVG
Messaggi: 28768
|
*indicizzato
|
|
|
|
30-09-2009, 12:49
|
#8 |
|
Senior Member
Iscritto dal: Jan 2002
Messaggi: 10012
|
Iscritto
|
|
|
|
30-09-2009, 12:52
|
#9 |
|
Senior Member
Iscritto dal: Sep 2008
Città: Provincia di reggio, costa dei gelsomini :D
Messaggi: 1691
|
Evvai!
Propongo Capitan crasy for president!
__________________
Amore mio, forza ed onore, io sono nel cuore tuo. Insieme ce la possiamo fare, a vincere questa battaglia per la vita |
|
|
|
30-09-2009, 13:15
|
#10 |
|
Member
Iscritto dal: Apr 2005
Città: Genova
Messaggi: 109
|
ping... iscritto
__________________
Cpus: C1 Athlon 3.2 Matrox G400 + NVIDIA8600 LCD19"+CRT 21" DH - C2 Athlon 3.2LV htpc case antec display LDC samsung 40'' - C3 slate Motion Computing LE1700 Musica: ls3/5a, monotriodo 300b, pre 6sn7, teac VRDS10, vari T-Amp da battaglia, Yamaha S90es Gadget: DS, Nokia 770, N800, N6021, N6210, N6220c, S Z720v, N900, X360 |
|
|
|
30-09-2009, 13:19
|
#11 |
|
Senior Member
Iscritto dal: Aug 2009
Messaggi: 4756
|
Iscritto! Vediamo che combina AMD con Fusion
__________________

|
|
|
|
30-09-2009, 13:24
|
#12 |
|
Senior Member
Iscritto dal: May 2009
Messaggi: 1330
|
Eccomi!
|
|
|
|
30-09-2009, 13:30
|
#13 | |
|
Member
Iscritto dal: Jan 2009
Messaggi: 58
|
Quote:
__________________
CPU Athlon64 X2 6000+-->PhenomII x2 550 MOBO SAPPHIRE PI-AM2RS780G RAM Kingston 2x4GB 6400 VGA Ati Radeon 4770 512Mb HD Seagate Barracuda 1500 gb SataII 64mb 
|
|
|
|
|
30-09-2009, 13:33
|
#14 |
|
Senior Member
Iscritto dal: Aug 2006
Messaggi: 11100
|
thread dovuto direi

__________________
PC1: LG 34UC79G - Ryzen 5600@4,65ghz CO-30 - MasterLiquid 240 - 32GB 2400 Corsair@3000 - Gigabyte GA-AB350M Gaming 3 - RX 6700XT - NZXT S340 Elite PC2: FX6300 - AC Freezer 64 pro - Gigabyte 990XA-UD3 - Sapphire HD7850 2gb - 8gb DDR3 Corsair 1333 - - Antec Two Hundred PC3: AMD A10 7700k - 8gb DDR3 2400mhz - SanDisk Plus SSD 240gb - CoolerMaster NSE-200-KKN1 |
|
|
|
30-09-2009, 13:46
|
#15 |
|
Senior Member
Iscritto dal: Apr 2005
Città: Napoli
Messaggi: 6794
|
Benissimo.
Io proporrei di cambiare il regolamento del thread sul K10 per reindirizzare i post su buldozer qui... Se il regolamento già lo contemplava, allora bisogna essere meno permissivi di la... Comunque... Iscritto!
__________________
0 A.D. React OS La vita è troppo bella per rovinarsela per i piccoli problemi quotidiani... IL MIO PROFILO SOUNDCLOUD! |
|
|
|
30-09-2009, 13:46
|
#16 |
|
Senior Member
Iscritto dal: Mar 2006
Messaggi: 8598
|
Seguo interessato
__________________
PlayStation 5 | Steam Deck 512 GB | Ryzen 7 7700 2x16GB Corsair Dominator Platinum 6400 MHz RTX 2070 Super Trattative OK: 1mp3r4t0r, armenico11, Babumba92, CoolBits, Drigerott, gino1221, k.o.z, Macco, Mastermarcox, Mone_82, stacker, Velvet, Vladimiro Bentovich, frupoli, Sheva77, deg626, HcK190, Godmar, Simonxp, LCol84, pp2k, xeno the holy, SamuTnT |
|
|
|
30-09-2009, 14:13
|
#17 |
|
Senior Member
Iscritto dal: Jul 2002
Città: Messina
Messaggi: 9258
|
Eccomi
__________________
T๏гקє๔๏_мυѕι¢_1 Asus Prime B450M-K ◌ AMD Ryzen 5 5900x ◌ 32Gb G. Skill DDR4 ◌ Zotac RTX 3060 Ti ◌ Corsair M.2 SSD [480Gb] T๏гקє๔๏_мυѕι¢_2 Asus Prime B450M-A ◌ AMD Ryzen 5 5600x ◌ 64Gb G. Skill DDR4 ◌ Palit StormX RTX 2060 ◌ Crucial M.2 SSD [2Tb] T๏гקє๔๏_мυѕι¢_3 Acer Nitro 5 AN515-57-7655 15.6" ◌ Intel i7-11800H ◌ 16GB DDR4 ◌ GeForce RTX 3060 ◌ M.2 SSD [1Tb] |
|
|
|
30-09-2009, 14:37
|
#18 |
|
Senior Member
Iscritto dal: Feb 2003
Città: Napoli
Messaggi: 2200
|
Presente anche io
Byez!
__________________
MacMini 2020 CPU M1 - GPU 8 Core - 8GB RaM - SSD 512GB | MacBook Pro 14" 2023 M3 Pro - GPU 18 Core- 18GB RaM - SSD 1TB | Synology DS916+ - DS213j | iPad Pro 11" 512GB WiFi+Cell | iPhone 15 Pro Max Titanio Bianco 256GB | Apple Watch Ultra 2 | Apple TV (4th gen) 32GB | Apple TV 4K 64GB | Canon EOS 100D |SeaBlog - Il blog del mare
|
|
|
|
30-09-2009, 15:21
|
#19 | |
|
Bannato
Iscritto dal: Jul 2008
Messaggi: 1998
|
Quote:
|
|
|
|

|
30-09-2009, 15:21
|
#20 |
|
Senior Member
Iscritto dal: Nov 2003
Messaggi: 24165
|
Grazie a tutti per i complimenti, sono davvero lusingato...
 Eccovi una chicca: Sappiamo che la prima piattaforma desktop con le CPU Bulldozer si chiamerà "Scorpius" Questa immagine la trovate sul sito AMD.
__________________
AMD Ryzen 5600X|Thermalright Macho Rev. B|Gigabyte B550M AORUS PRO-P|2x16GB G.Skill F4-3200C16D-32GIS Aegis @ 3200Mhz|1 M.2 NVMe SK hynix Platinum P41 1TB (OS Win11)|1 M.2 NVMe Silicon Power A60 2TB + 1 SSD Crucial MX500 1TB (Games)|1 HDD SEAGATE IronWolf 2TB|Sapphire【RX6600 PULSE】8GB|MSI Optix MAG241C [144Hz] + AOC G2260VWQ6 [Freesync Ready]|Enermax Revolution D.F. 650W 80+ gold|Case In Win 509|Fans By Noctua|¦ Ultima modifica di capitan_crasy : 30-09-2009 alle 15:23. |
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 02:40.


_XXL.jpg)













