Quote:
di solito, per esperienza mia eh, quando in un esercizio trovi queste incongruenze è perchè è sbagliato il testo di partenza. |
Quote:
Ad ogni modo per me è un esercizio "interessante". Lo studente dovrebbe notare che nelle eq. differenziali è importante anche la soluzione particolare e in questo caso è l'unica che da un contributo alla soluzione con quelle condizioni iniziali :D L'altra possibilità è che abbiano effettivamente sbagliato i dati dell'esercizio ma poco importa:D |
appunto perchè quel "2*y(3)" non ha niente di complesso mi porta a credere che non sia stato messo lì apposta...
poi hai ragione, poco importa... era solo per parlare un po' :D |
salve, avrei un problemino con quest'identità goniometrica
sapendo che: pi=a+b+g pi=pi greco dimostra questa identità sen(a)+sen(b)+sen(g)=4cos(a/2)cos(b/2)cos(g/2) dopo una miriade si passaggi (non sono sicuro al 100% siano giusti) sono arrivato a: sen(a)+sen(b)+sen(g)=0 e ora???:mc: bella rogna!:muro: |
edit: risolto da me :D
|
cercavo un esempio chiaro sulla "statistica sufficiente" :fagiano:
Una statistica sufficiente è una funzione che sintetizza l'informazione contenuta nel campione: ma che significa ? :) |
Quote:
Dove nel secondo termine ho sfruttato la relazione a+b = pi - g e il fatto che sin(g)=sin(pi-g). Sempre nel secondo termine, puoi riscrivere a+b = 2*(a+b)/2 e applicare la formula per sin(2x). Nel secondo passaggio ho raccolto il seno, e ho sfruttato le relazioni (a+b)/2 = pi/2 - g/2 e sin(pi/2 - x) = cos(x). Ora è sufficiente svolgere i coseni nella parentesi per ottenere il risultato. Quote:
|
in effetti ho rifatto i calcoli e sen(a)+sen(b)+sen(g)=0 è sbagliato, non ho provato con il tuo metodo però sono riuscito a risolverlo ponendo a=pi-(b+g) e quindi sostituendo tutte le a all'inizio gonfia, ma poi si semplifica tutto...
e viene 0=0 identità riuscita XD |
qualcuno di voi ha esercizi svolti (in internet) sul teorema di rice-shapiro e la sua applicazione?
|
scusate la domanda molto idiota per la stragrande maggioranza di voi.
quando ho una frazione del tipo radice quadrate di c / radice quadrata di c2 per eliminare le radici e quindi semplificare i successivi calcoli, posso elevare a potenza entrambe?o un operazione matematicamente errata? |
se la frazione fa parte di un'equazione, cioè frazione=qualcos'altro, allora puoi elevare entrambi i membri, ma prendere la frazione a se stante ed elevarla al quadrato nn ha senso.
|
ho ancora dubbi sulla variabile aleatoria!
Si dice che la media campionaria è una variabile aleatoria e come tale ha la sua media e varianzae altro. Si legge anche che la media campionaria è difinita come  . .Mi chiedevo: se ogni Xi rappresenta un evento, esempio l'altezza delle persone: X1(carlo)=1.75 X2(beatrice)=1.70 X3(giorgio)=1.80 usando la formula che ho indicato, otterrei la media di queste 3 altezze; ma siccome si dice che la media campionaria è una v.a. per determinare la sua distribuzione avrei necessitò di più eventi separati ? |
Quote:
ad ogni modo per valutare la distribuzione ti servono più realizzazioni differenti e possibilmente il piu possibile. Una volta effettuate tutte le realizzazioni le plotti come grafico a diospersione XY o come grafico a barre assumendo per esempio che l'altezza di carlo non sia 1,75 ma compresa tra 1,725 e 1,775 quella di beatrice tra 1,675 e 1,725 ( insomma associando una determinata realizzazione ad un intervallo non un numero esatto). Una volta disegnato ci sono piu metodi per stimare i vari dati es: se supponi che la distribuzione sia exp del tipo F(x)=1-e^-at allora elaborando un attimo hai che ln(1/(1-F(x)))=at che è una retta!! plotti le tue realizzazioni e delle tue realizzazioni valuti la retta interpolante ad esempio con il metodo dei minimi quadrati. Una volta fatto questo se vedi che i tuoi punti fittano bene la retta hai una possibile distribuzione che ti descrive i tuoi dati che è quella exp con parametri a= pendenza della retta interpolante. Se non ti fitta bene i dati provi con altre distribuzioni: T-student, Weibull, lognormale etc etc naturalmente adattando opportunamente gli assi per avere una retta. |
Quote:
radice di c / radice di c2 = p1/p2 devo elevare tutto al quadrato? sia a dx che sx? oppure posso elevare solo radice di c / radice di c2? |
Quote:
intendevo che prendo un gruppo di persone a milano e ne faccio la media, un gruppo a roma e ne faccio la media e poi faccio la distribuzione della media campionaria con tutte queste medie. Quindi avrei che: con i vari m1, m2,..,mn (medie dei campioni) calcolo media e varianza campionaria e poi traccio la gaussiana. Quello che ho notato generando 1000 campioni casuali e poi facendone la media di tutti e 1000, ottengo quella che viene definita la media della popolazione. Se di quei 1000 campioni ne estraggo un certo numero di gruppi e poi ne faccio la media, ottengo per ogni gruppo medie diverse che sono dovute al caso, ma poi se le medio tutte riottengo la media della popolazione. Questo fatto mi ha suggerito che la formula che ho citato in precedenza per ogni Xì, sia che identifichi una media di un campione che un singolo valore ciò che si ottiene è la stessa cosa, mi spiego: ero convinto che per fare la distribuzione campionaria che è una variabule aleatoria, si dovesse necessariamente creare tante medie e poi mediarle successivamente ma, dopo l'esperimento che ho condotto il risultato è il medesimo. La morale allora è che se si da retta a quanto recita il teorema del limite centrale, per un numero n abbastanza grande di dati la distribuzione campionaria tende ad una distribuzione normale. Scusa ma è due giorni che litigo col significato di variabile aleatoria. So che è una funzione che associa un elemento dello spazio campionario ad un numero sulla retta reale, ma che mi depista nel momento in cui si dicono cose del tipo: dato un campione (X1,X2,...,Xn) In questo caso non si capisce se nella definizione per ogni v.a. deve competere ad esempio una sola altezza di una persona oppure se ogni Xn rappresenta una distribuzione con la sua media e la varianza. Guardando la formula citata che è poi uno stimatore, mi viene da dire che ogni Xn è una distribuzione che può essere fatto da 1 a n elementi ciascuna. Facendone la sommatoria poi, il risultato non cambia se si considerano le varie Xn costituite da 1 o più campioni. La morale è che grazie al limite centrale la media campionaria può essere pensata come fatta da tante altezze delle quali farne la media oppure da tante medie di cui farne la media ed il risultato è il medesimo. Scusa ma spero di essermi espresso in modo chiaro, anche se ho più di qualche dubbio :stordita: |
solo una domanda. Cosa intendi per campione? un GRUPPO/lotto di estrazioni o una Singola estrazione per intenderci?
|
Quote:
Io ho sempre pensato che ad ognuna corrispondesse ad esempio una gaussiana. Messa in questo modo quando calcolo il valore atteso 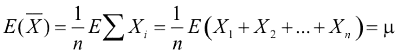 allora è una somma di v.a. e quindi una somma di funzioni allora è una somma di v.a. e quindi una somma di funzioniPer ogni variabile aleatoria di qualunque distribuzione sono definiti due parametri: la media mu che è la media dei valori che la variabile aleatoria può assumere: la varianza sigma^2 che indica la concentrazione intorno alla media della variabile aleatoria, la sua radice quadrata sigma è detta deviazione standard . |
ragazzi scusate ma ho un'altra domanda scema:
3 ln(x) + ln(x2) in base ad una proprietà dei logaritmi equivale a x^3 + x2 ? |
Quote:
3 ln(x) + ln(x2) = ln(x^3*X2) se con X2 intendevi dire x^2 allora 3 ln(x) + ln(x^2) = ln(x^3*x^2)=ln(x^5)=5*ln(x) |
Quote:
se X1,...Xn sono REALIZZAZIONI di una variabile aleatoria ( quindi numeri) allora puoi stimare la media e la varianza della stessa e ipotizzare una certa distribuzione e questo è quello che ho scirtto prima se X1, .... Xn sono Variabili aleatorie quindi funzioni con una certa distribuzione TUTTE con la stessa distribuzione comune F(x) e media µ è una VARIABILE ALEATORIA detta media campionaria o media campione.come tale si puoo calcolare il valor medio come hai riportato dove µ è appunto per definizione la media della F(x) comune a tutte le Xi, e anche la varianza dell amedia campionaria che è pari alla varianza della F(x) diviso n. |
Quote:
ma 3 ln(x) + ln(x2) in nessun modo può essere trasformato in x^3 + x2? PS con x2 intendo X due (bene 2, mentre x bene 1) |
Quote:
le uniche certezze che ho stanno nelle definizioni. Nel mio corso si fa distinzione tra X grande e x piccola dove con X grande ma vale anche per tutte le altre lettere si definiscono le variabili aleatorie e quindi sono funzioni, con lettere piccole invece le varie realizzazioni che sono numeri. Essendo una v.a. dotata di media e varianza e quindi una funzione, la media campionaria è ottenuta sommando funzioni esempio gaussiane e non singoli valori. :muro: |
Quote:
X1(carlo)=1.75 X2(beatrice)=1.70 X3(giorgio)=1.80 :D . Inoltre c'e una altro piccolo problema. Si chiama media campionaria anche nel seguente caso. Metti di voler stimare la media della popolazione italiana, tu non lo fai su tutte le persone ma prendi un campione rappresentativo di 1000 persone ad esempio e calcoli la media delle altezze, se hai scelto in modo opportuno il campione allora la media sarà rappresentativa della media di tutta la popolazione italiana. Questa media si chiama anc'essa media campionaria :fagiano: |
Quote:
|
Quote:
Se ora calcolo la media e la varianza di ogni v.a. ottengo dei valori privi di significato, ma se ne uso tanti e poi ne faccio la media, posso costruire la media campionaria e quindi la sua distribuzione. Quote:
Ora quasi capisco cosa intende il teorema del limite centrale che all'aumentare dei campioni qualsiasi distribuzione tende ad una normale. Nel caso di beroulliane avremo funzioni che sono formate da un solo punto per v.a. mentre nel caso di gaussiane più punti(realizzazioni) per v.a. Spero sia così :muro: grazie francy |
Quote:
sono problemi microeconomici quindi x1 è il bene 1 e x2 è il bene 2 |
Quote:
|
Quote:
|
Quote:
tra matematica e microeconomia ci ho un casino in testa che non hai proprio idea Quote:
|
secondo voi
se lancio 50 volte una moneta e scrivo il numero di volte che esce testa e lo chiamo x1=35 Ripeto l'esperimento e lo chiamo x2=10 e vado avanti così per 10 volte. Prendo quindi tali variabili e ne faccio la media. media campionaria=(x1+x2+...+x10)/10 Ora classifico le prove per frequenza usando degli intervalli e quindi ne traccio un istogramma: perchè non assomiglia per nulla ad una distribuzione gaussiana ? Ho provato con 2000 campioni e nemmeno in questo caso ottengo una gaussiana approssimata :stordita: |
Quote:
Il problema è che la teoria dice per n-> inf quindi è critico dire " ok ne ho gia fatti abbastanza" :D inoltre: con cosa hai generato i numeri casuali? quello di excel e dei computer sono numeri PSEUDOcasuali non casuali e potrebbero falsarti il tutto |
Quote:
ho usato un programma di due righe in VBA con la funzione random() il risultato è pessimo :( p.s. ignora i nomi delle colonne che non fanno fede |
mi sa che hai ragione francy, il randomize di excel non va bene
p.s. c'era un errore di valutazione, ora funziona perfettamente :) http://img181.imageshack.us/img181/8939/imgbb6.gif chi la dura la vince 1000 lanci di una moneta |
 Non so come risolvere questi sistemi per ottenere gli autospazi :cry: :cry: |
qualcuno se ne intende di lambda calcolo, beta riduzioni e forma normali?
ho queste slide: http://dit.unitn.it/~zunino/teaching/computability.pdf pagina es n° 59 di pagina 17 (21 del pdf) Codice:
KIKCodice:
Sì: Icome si può capire nn mi è chiaro come si gestiscono le parentesi, es: K (KI) I: cosa diventa? KI? se avessi K (IK) I sarebbe prima da svolgere la parentesi quindi K I I e poi quindi I? La forma normale si raggiunge quando nn è più possibile ridurre es I, ma se ho KI è in forma normale (serve un altro valore per poter ridurre ancora)? |
Tanto per rimanere su algebra lineare, chi mi dice in parole povere, proprio terra terra, come si calcola la molteplicità algebrica di un autovalore?
Senza formule o dimostrazioni...solamente una spiegazione rapida:stordita: E' quante volte il valore (lamda) si ripete? Ad esempio perchè se su lamba= 4 l'autovalore è 2 (OK) e su un altro esercizio mi ritrovo lambda1 = 0 e lamba2 = 1, con lamba1 di molteplicità 1 (OK) e lamba2 ha moletplicità 2??? |
HELP!! STUDIO FUNZIONE!!! :D
Y=logx /(1-x) D: x E (0;1)U(1;+INFINITO) ZERI: NON CE NE SONO!!! LOG X = 0 per x=1... ma 1 non appartiene al dominio! segno della funzione... sempre negativo.... log x>0 x>1 1-x >0 x<1 .... quindi tutto negativo ASINTOTI: lim x->1- mi viene -1 (hopital) lim x->1+ mi viene -1 (hopital) lim x-> + infinito mi viene 0 as obliquio non c'e... perche k mi viene = a 0 la derivata prima mi viene un bordello : S potreste scrivermi derivata prima lo studio della monotonia (max min) e la derivata seconda?? (studio flessi) grazie.. a me sono venute porcate.. c'e :s proprio non so manco cazzo ho scritto!!!:help: :help: :doh: :D |
la derivata prima è
[1/x*(1-x)+logx]/(1-x)^2 = [(1-x)+x*logx]/[x*(1-x)^2] non mi sembra tanto complicata :stordita: |
Quote:
ecco si vabbene:O ! ma il mio problema è che non riesco a porlo = 0 c'e nel senso : s non so come cappero dire per che x la derivata prima e uguale a 0! mi viene la derivata : [(1-x)/x]+log x/(1-x)^2 ora pongo il numeratore = a 0 ma non so come risolvere [(1-x)/x]+logx=0 e mo che faccio?? XD |
Quote:
O sviluppi il logaritmo in serie di Taylor o fai delle considerazioni sugli intervalli dove puoi trovare le soluzioni. |
| Tutti gli orari sono GMT +1. Ora sono le: 00:13. |
Powered by vBulletin® Version 3.6.4
Copyright ©2000 - 2024, Jelsoft Enterprises Ltd.
Hardware Upgrade S.r.l.