





|
|||||||


|


|
|
 |
|
|
Strumenti |
 17-05-2024, 13:46
17-05-2024, 13:46
|
#1761 | |
|
Senior Member
Iscritto dal: Sep 2020
Messaggi: 5201
|
Quote:
__________________
GPUMSI 4090 Suprim Liquid X - CPU R7 7800 X3D - SCHEDA MADRE MSI X670E Meg ACE -RAM Gskill 32 gb ddr5 6400mhz- SSD Sabrent Rocket4 Plus 2TB- SSD 980 pro 2 TB- CPU COOLER Lian Li Galahad V2 360- ALIMENTATORE MSI MEG PCIe5 ATX3.0 1000 W- CASE Theramltake Core P3 TG Pro TV/MONITOR Lg Oled G3 55"/Samusng G9 49" PC Numero 2 https://ibb.co/BCBgZHP |
|

|

|

|
17-05-2024, 17:09
|
#1762 | |||||
|
Senior Member
Iscritto dal: Mar 2007
Messaggi: 20934
|
Quote:
Con zen6 si dovrebbe svoltare sulle latenze tra CCD, e vogliamo tornare ai CCX. Riguardo il 8700g, grazie alla struttura CCD, mantiene tutti rapporti core to core ed IPC di zen4, ma dove serve la cache, sbanda terribilmente, vedi giochi e compressioni. Chiaro, va bene nel calcolo, come anche un CB, ma li pure con 96mb di cache non guadagni. 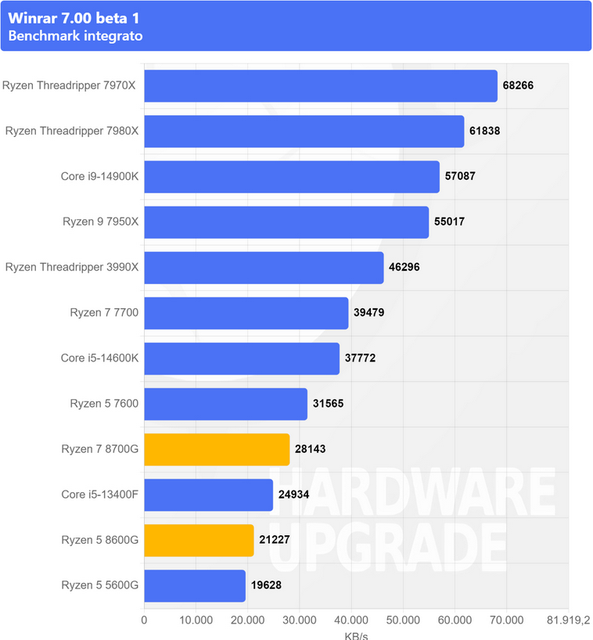 Quote:
Se tu avessi 10ghz, anzichè 5, avresti 2x la banda l1/l2/l3. Quella non viene tagliata. Con le ram più veloci, tramite ghz/latenza avrai valori migliori, ma questo è un'altra cosa. Quote:
Come vedi sui 32 core, raddopierà pure la l3 che è oltre 1/3 di die. Intel infatti, per collegare gli e core, gli ha aumentato la l3, ed ha dovuto bombardare di l2 (che è molto più grossa della l3) per evitare che gli ecore si mangiassero la loro l2 e saturassero buona parte di l3. I p-core, se non avesso gli e core, avrebbero 24mb di l3 e 16mb di l2. Con gli e core, passano a 36mb di l3 e ben 32mb. Di fatto raddoppiano la l2 e 1,5 la l3. Come vedi, per mantenere quei core extra, devono bombardare di cache, non a caso raptor è una padella da quasi 260mm2, roba da rtx 4070ti quasi. Inoltre gli e core non sono come i core dense, sono stati proprio una pezza, in quanto era inconcebile mettere 16 p core, altrimenti non ricorevvi a questo. Lo sai che la latenza ibrida core to core è equivalente a quella di zen2? L'ibrido volendo potresti pure farlo su AMD, tramite un CCD basic ed uno Dense, oppure, non potendo dividere in 2 CCX, colleghi un 8+16 ad una cache molto più grande, ed ecco che ti serve densità. Il calcolo che fai tu, è trovare un modo per avere performance brute, sacrificando l'IPC e il ST a scappito del puro MT. Quote:
Con i 3nm, hai densità sufficiente a poter realizzare un 16 core totale, ma il problema resta sempre la cache l3. Salvo non lanci le CPU già impilate. Per farti un'esempio, 8 core zen4, hanno densità di 92mtx mm2 su 30mm2. 16 core zen4 per farceli stare su 30mm2, ti servirebbe 184mt xmm2 (densità da 3nm), e purtroppo la cache non viene dimezzata con i 3nm, quindi per passare a 64 dovresti allargare il CCD. Ovviamente su zen4, ma con i prossimi i transistor saranno molti di più per core. Quote:
__________________
Ryzen 5800x3D - Msi B450TH - Corsair 32gb 3600 lpx - RTX 3080 FE - samsung 860 pro 1tb - 4tb storage - Acer g-sync xb270hu - XFX 850 watt - tim 200/20 mbps. |
|||||
|
|
|
|
17-05-2024, 17:26
|
#1763 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30368
|
K. Devo assimilare
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M |
|
|
|
|
17-05-2024, 21:00
|
#1764 | ||
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30368
|
Intanto c'è una chicca, che se confermata sarebbe una botta pazzesca.
Il rendering AMD Strix Halo rivela il potente design dell'APU Ryzen: 16 core Zen 5, 40 core GPU RDNA 3+, cache L3 da 64 MB Quote:
Fino a 16 core 64 MB di cache L3 condivisa 40 unità di calcolo RDNA 3+ Cache MALL da 32 MB (per iGPU) Controller di memoria LPDDR5X-8000 a 256 bit Motore XDNA 2 integrato Fino a 70 AI TOP 16 corsie PCIe Gen4 Lancio della seconda metà del 2024 (previsto) Piattaforma FP11 (55W-130W) Tenete presente che un 7700X arriva a 142W PPT, questo è un X16 con una iGPU da 40 CU e arriverebbe al massimo a 130W. Certo che (se vero) sto N4P tirerebbe da bestia. Quote:
https://wccftech-com.translate.goog/...t&_x_tr_pto=sc Altre info da leggere qui. https://www-pcgamesn-com.translate.g...t&_x_tr_pto=sc https://hothardware-com.translate.go...x_tr_hist=true   Qui invece Ryzen AI 9 HX 170 “Strix Point” https://hardwaretimes-com.translate....t&_x_tr_pto=sc 
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M Ultima modifica di paolo.oliva2 : 17-05-2024 alle 21:26. |
||
|
|
|
|
17-05-2024, 23:13
|
#1765 |
|
Senior Member
Iscritto dal: Mar 2002
Messaggi: 1669
|
per lo piu' e' un riassunto dei vari rumor precedenti, di nuovo pare che forse all'interno del GCD ci sono anche dei core LP, ma se vero, a che pro, in che quantita' e configurazione..sperem per il computex
interessante il nuovo collegamento INFO tra chiplet e GCD, forse mikael puo' delucidarci, magari migliora proprio alcuni tipi di latenze..
__________________
La legge di Moore è morta, sostituita dalla legge di Huang Le gpu raddoppieranno di prezzo ogni due anni.. 
|
|
|
|
|
Ieri, 07:34
|
#1766 | |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30368
|
Quote:
Forse li chiamano LP perchè il chiplet essendo prodotto sull'N4P, non è possibile realizzare Zen5C che abbisogna dell'N3E... La chiarificazione che il chiplet di questi è diverso dal Granite non è insignificante... perchè già di per sè se questi chiplet mobili integrano core LP (CON LO STESSO CORE-COUNT dei chiplet desktop), è palese che i chiplet Granite con tutti core "normali" e non una parte LP, le prestazioni sarebbero maggiori. Io non voglio creare castelli in aria e aspettative smisurate... ma se l'IPC di Zen5 mobile è valutato come media con core normali ed LP e su frequenze dei core "normali", è ovvio che risulti inferiore al reale, mi parrebbe sballato e questo giustificherebbe il rumor di IPC ben superiore di Granite. Poi riportare la banda con una comparazione è utile per il 99% delle persone che non ha un'idea delle bande delle discrete e delle DDR alternative. Se consideriamo che la soluzione AMD LPDDR5X 256 offre quasi 3X la banda delle DDR5 6400 e in linea con le discrete medio-basse, direi che molti dei pregiudizi sulle prestazioni grafiche massime degli APU vadano a finire nel cesso. Tra l'altro quella monetina a fianco dei 2 die, ha una dimensione tra le monetine da 2 e 1 centesimo di € (vedi mia foto sotto, la monetina USA è simile a quella inglese)... ed i 2 chiplet Zen5 X8 ci stanno tranquillamente nell'area di quella moneta... e fa supporre che l'IOD di Zen4 abbia un'area simile all'IOD + GPU40CU di questo Zen5... impressionante, perchè nel salto all'N3E, AMD potrebbe metterci una iGPU ancor più grande e/o un core-count superiore, e visto che AMD sta già producendo sull'N3E i chiplet densi Zen5C, i tempi potrebbero essere rapidi... ed ancor più sull'N2... per AMD è solamente questione di scelta commerciale di quello che potrebbe fare.  Per quello che riguarda il collegamento tra chiplet e IOD, è lo stesso di Zen4. Quello che può cambiare sono le frequenze dell'IF, le linee PCI si sa già che saranno inferiori a quelle desktop, e idem l'I/O. Per Zen6 si parla di PCI6 (almeno per trasferimento interno CPU)... dubito sia implementato su Zen5. La latenza in sè sarà sempre superiore rispetto ad un monolitico, perchè il segnale deve essere convertito sull'IF alla partenza (chiplet) e riconvertito all'arrivo (IOD), ma la latenza ha un valore suo, perchè dipende dalla velocità e da altro del circuito rimanente. Avere DDR5000 a CL40 (latenza) non è meglio rispetto a DDR10000 a CL42, come del resto l'L3 3D aumenta di poco la latenza della L3, ma aumenta e di molto il risultato dove la L3 conta. Sono 2 casi esempio che con una latenza superiore si ottiene un risultato comunque migliore.
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M Ultima modifica di paolo.oliva2 : Ieri alle 08:23. |
|
|
|
|
|
Ieri, 09:23
|
#1767 | ||||||
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30368
|
Ho dovuto leggere più volte per arrivare a capire ciò che scrivi (ovviamente per carenze mie).
Quote:
Il confronto è si giusto, però, a mio parere, AMD non ha fatto nulla per migliorare in quanto non era certo negli obiettivi AMD far competere l'8000G vs i 7000. L'8000G ha usato il PP più denso a scapito della frequenza e una L3 16MB e non a 32MB o impilata aggiuntiva per ovvi prb dei costi, perchè avrebbe fatto miracoli. Strix ok che porta una L3 a 32MB x 8 core, però tanto arriva (pare) dall'N4P Quote:
AMD quando taglia la L3 da 32MB a 16MB, non migliora la latenza come potrebbe... ed è ovvio che se confronti due L3 a pari latenza ma 16MB vs 32MB i core ne risentano molto di più che se 16MB/latenza 20 vs 32MB latenza 40. Cioè... una L3 a metà latenza equivale come avere DDR5 a frequenza doppia. Se ho L3 latenza 20 + DDR5 5000 = L3 latenza 40 DDR5 10000 (penso, perchè da una parte raddoppi la latenza e dall'altra raddoppi la banda). Quote:
Facendo un esempio... un X96 Zen4 ha pur sempre lo stesso CCX di un 7950X, la stessa L3/L2 e quant'altro, quello che cambia è che si passa da un double-channel AM5 ad un dodeca-channel Epyc. Quindi il core-count CPU aumenta aumentando la banda DDR, ma lasciando il resto invariato. Mi sfugge quale sarebbe la differenza tra un 7950X con DDR5 4800 double-channel, che con DDR5 9600 otterrebbe una banda simile al quad-channel sempre DDR5 4800. Idem è lo stesso facendo i conti su un Zen5 sulla base di Zen4 e DDR5 EXPO 6000... secondo me così è creare dei limiti a priori... sarebbe come con gli APU dicendo che con DDR5 la banda massima è 100GB/s, quindi l'iGPU è castrata e quindi una 40CU risulterà un cesso, e poi scappa fuori che in Strix Halo l'iGPU avrebbe 270GB/s... quasi 3X la banda delle DDR5 6400 in AM5... è ovvio che il limite teorico iniziale era un pregiudizio. Per me il discorso è più semplice... il CCX deve superare l'X8... come prima era X4 ed AMD l'ha portato a X8, ora lo deve portare a X16 se non X32. Non so come varia la banda intercore... ma mi pare che il problema riguardi più inter CCX/inter L3 che inter-core all'interno del CCX. La L3 non è un prb per me... o almeno non è un problema per AMD perchè con l'impilazione non ha alcun problema di ottenere una capacità superiore (doppia o tripla) dipendente dalla densità nanometria utilizzata. Quote:
Quote:
Secondo me ragiogniamo su dei limiti che in realtà non ci sarebbero. Intel realizzava max un X24 (mi pare) monolitico, con rese ~45% di die perfetto... e realizzava una CPU con il doppio dei core a mo' di Core2. AMD con l'MCM ha raddoppiato il core-count, portando un X96 a costi e rese da Chiplet X8. Perchè aspettare un 2nm per un chiplet X16 quando oggi lo potrebbe già fare con l'impilazione? Quello che AMD con TSMC (OGGI) non fa, non è perchè impossibile, ma perchè non commerciabile (perchè la features costerebbe troppo). Quote:
P.S. Che io abbia fantasia (molta) non lo metto in dubbio. Però cerchiamo di uscire fuori da certi pregiudizi. Non riesco a comprendere perchè ancora oggi se si parla di AMD, ci facciamo dei limiti su limiti attuali come se AMD non abbia dimostrato nulla (esempio L3 3D)... mentre se parliamo di Intel, viene quasi automatico ipotizzare che se Intel non avesse il prb silicio, chissà cosa starebbe realizzando... dimenticando o volutamente ignorando che l'innovazione degli ultimi anni è targata esclusivamente AMD, in quanto l'brido Intel oggi c'è solamente perchè Intel ha le fab e i dindi, qualsiasi altra azienda che avrebbe prodotto l'ibrido Intel da TSMC/Samsung/GF, sarebbe fallita dopo 3 mesi, senza i super-clock di Intel7 cosa avrebbe fatto un 12900K sul 7nm TSMC (Intel7 = 7nm TSMC) in lotta con Zen3?
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M Ultima modifica di paolo.oliva2 : Ieri alle 10:04. |
||||||
|
|
|
|
Ieri, 09:42
|
#1768 |
|
Senior Member
Iscritto dal: Mar 2002
Messaggi: 1669
|
La foto con la monetina riporta vega e Fiji per un confronto
e halo sarà simile I core lp sono riportati sul i/o gcd, dovrebbero essere core extra oltre chiplet Anche Meteor mi sembra di ricordare ha qualcosa di simile ma sono rumor, da prendere con scetticismo Ma pare che il leaker e' un tipo affidabile, parla anche del collegamento INFO tra chiplet e gcd i/o, che era previsto per zen6 ma conferma che halo lo avra' per primo Collegamenti Infinity Fanout Il link di hothardware ne parla, con un approfondimento su rdna3 dove e' già usato https://hothardware-com.translate.go...t&_x_tr_pto=sc https://hothardware.com/Image/Resize...big_fanout.jpg
__________________
La legge di Moore è morta, sostituita dalla legge di Huang Le gpu raddoppieranno di prezzo ogni due anni..
Ultima modifica di ionet : Ieri alle 09:50. |
|
|
|
|
Ieri, 20:02
|
#1769 | |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30368
|
Quote:
 Nel funzionamento Zen, non ho idea di cosa possano fare dei core LP nel GDC, a me pare strano... Anche in Zen4 la iGPU è nell'IOD, perchè è la posizione più naturale, accanto alle linee PCI, all'MC ed a tutto l'I/O, senza alcuna necessità di collegamenti IF che aumenterebbero le latenze. Anche perchè se non la metti nell'IOD, per forza di cose faresti un 4 die di package, perchè i Chiplet non hanno I/O... con tanto di aumento latenze e consumi (il 4° die deve essere comunque collegato) e costi plus di package. Non è che avendo letto nella descrizione Zen5 LP sull'IOD/iGPU (ultima riga nella 1a foto) qualche "furbo" ha pensato che i core LP sono li?
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M Ultima modifica di paolo.oliva2 : Ieri alle 20:17. |
|
|
|
|
|
Ieri, 21:42
|
#1770 |
|
Senior Member
Iscritto dal: Mar 2002
Messaggi: 1669
|
quella foto e' storia, e' stata fatta quando hanno presentato Vega, e il confronto era con Fiji
e' stata riportata come esempio e forte similitudine per come Halo dovrebbe apparire https://hothardware-com.translate.go...t&_x_tr_pto=sc per il resto attendiamo il computex, manca poco
__________________
La legge di Moore è morta, sostituita dalla legge di Huang Le gpu raddoppieranno di prezzo ogni due anni..
|
|
|
|
|
Ieri, 22:09
|
#1771 |
|
Senior Member
Iscritto dal: Sep 2008
Messaggi: 12713
|
Quelle sono solo GPU... Strix Halo dovrebbe essere un APU completa con LPDDR5X condivise per cpu e gpu.
Il layout dovrebbe essere questo e sembra essere una bella padellina:   https://www.techpowerup.com/321693/a...56-bit-lpddr5x
__________________
i7 3930K @4.51Ghz  | Deepcool Assassin III | Asus x79 Rampage IV E | 4x4GB GSkill 1600Mhz C9 @2188mhz C10 | Manli | Deepcool Assassin III | Asus x79 Rampage IV E | 4x4GB GSkill 1600Mhz C9 @2188mhz C10 | Manli  RTX 3060ti @1905/1995Mhz - MEM @17Gbps | Crucial MX500 500 GB | 2tb WD Caviar black | EVGA SuperNova G2 750w | NZXT H510 Elite | Gigabyte G34QWC | Windows 11 Pro RTX 3060ti @1905/1995Mhz - MEM @17Gbps | Crucial MX500 500 GB | 2tb WD Caviar black | EVGA SuperNova G2 750w | NZXT H510 Elite | Gigabyte G34QWC | Windows 11 Pro  | TIME SPY | TIME SPY
Ultima modifica di Ubro92 : Ieri alle 22:12. |
|
|
|
|
Ieri, 23:41
|
#1772 |
|
Senior Member
Iscritto dal: Jan 2002
Città: Urbino (PU)
Messaggi: 30368
|
Io le VGA non le seguo... però lì riporta i chiplet non l'N4X e l'IOD/iGPU con l'N4P...
La 7700X è sul 5nm con 54CU è 346mm2 e 245W. La 7600X è sul 6nm con 32CU è 204mm2 e 190W. A me pare una esagerazione 200mm2 per 40CU su un 4nm che è un totale più denso del 5nm ed ancor più del 6nm. Comunque dando per buono i chiplet X8 a 80-85mm2 e IOD/iGPU a 200mm2, il totale verrebbe 360/370mm2. Che sia grande non si discute... però considerando che un 7950X è 264mm2 e che 20-30mm2 in più sono per i chiplet Zen5, alla fine AMD ci ha messo una 40CU al posto della 2CU di Zen4 in solamente 70/80mm2 in più... un successone (dovuto al 4nm TSMC). Ovviamente è un primo passo per AMD, ma visto che in 1 max 2 anni si passerà dal 4nm al 3nm e poi al 2nm, i 170W di oggi con 40CU domani potranno essere sempre 170W ma con 60CU oppure 120W con 40CU. Se la soluzione banda di AMD manterrà le promesse, beh... è una soluzione realizzata in MCM, quindi l'area è quella che è ma la resa è quella dell'MCM, fosse un monolitico da 360/370mm2 sarebbe ben diverso, e poi bisogna vedere la risposta degli OEM, perchè potenziando la iGPU dell'APU a 40CU, vuol dire un tot in più di modelli con prestazione grafica superiore senza dover optare per una VGA mobile on boad, il che vuol dire meno magazzino per gli OEM, progettazione mobo più semplice, progettazione dissipazione su 1 solo punto e non 2, portatile più leggero, meno superficie calda sul mobile... ed è ovvio che un APU con 40CU costi meno all'OEM vs un apu + VGA on board da 40CU. Di pro ce ne sono un tot, di contro... solamente se rispetta le aspettative... ma già il fatto di portare questa soluzione in produzione di massa, mi pare pressochè certa la qualità.
__________________
7950X - X670E Asrock PG - Aio 360 Thermaltake - RS/DU TDP max 230W - CB23 39.117 https://ibb.co/M9j2bV7 - CPU-Z 815/16427 https://valid.x86.fr/jdgu90 - No overdrive - OCBench NO RS CB23 40.697 https://ibb.co/W0qnRQB - Codifica video https://ibb.co/Jm5Zj0M Ultima modifica di paolo.oliva2 : Oggi alle 00:10. |
|
|
|
|
|
| Strumenti | |


|
|

Tutti gli orari sono GMT +1. Ora sono le: 02:58.















